モデルのファインチューニング
AI モデルのファインチューニングは、GPU を備えたコンピューティング環境で、事前学習済みモデルに対してカスタムデータセットを使用して ファインチューニング ジョブを実行できる一般的なプラクティスです。AI Toolkit は現在、ローカル マシン (GPU 付き) またはクラウド (Azure Container App、GPU 付き) での SLM のファインチューニングをサポートしています。
ファインチューニングされたモデルはローカルにダウンロードして GPU で推論テストを実行したり、CPU でローカルに実行するために量子化したりできます。ファインチューニングされたモデルは、リモート モデルとしてクラウド環境にデプロイすることもできます。
VS Code 用 AI Toolkit (プレビュー) で Azure 上の AI モデルをファインチューニングする
VS Code 用 AI Toolkit は、モデルのファインチューニングの実行とクラウドでの推論エンドポイントのホストのために、Azure Container App をプロビジョニングする機能をサポートするようになりました。
クラウド環境のセットアップ
-
リモート Azure Container Apps 環境でモデルのファインチューニングと推論を実行するには、サブスクリプションに十分な GPU 容量があることを確認してください。必要な容量をアプリケーション用にリクエストするには、サポート チケットを送信してください。GPU 容量に関する詳細情報
-
HuggingFace 上でプライベート データセットを使用している場合、またはベース モデルにアクセス制御が必要な場合は、HuggingFace アカウントを持っていること、およびアクセス トークンを生成していることを確認してください。
-
Mistral または Llama をファインチューニングする場合は、HuggingFace で LICENSE に同意してください。
-
VS Code 用 AI Toolkit でリモート ファインチューニングと推論の機能フラグを有効にする
- ファイル -> 設定 -> 設定 を選択して、VS Code の設定を開きます。
- 拡張機能 に移動し、AI Toolkit を選択します。
- "Azure Container Apps でファインチューニングと推論を実行できるようにする" オプションを選択します。
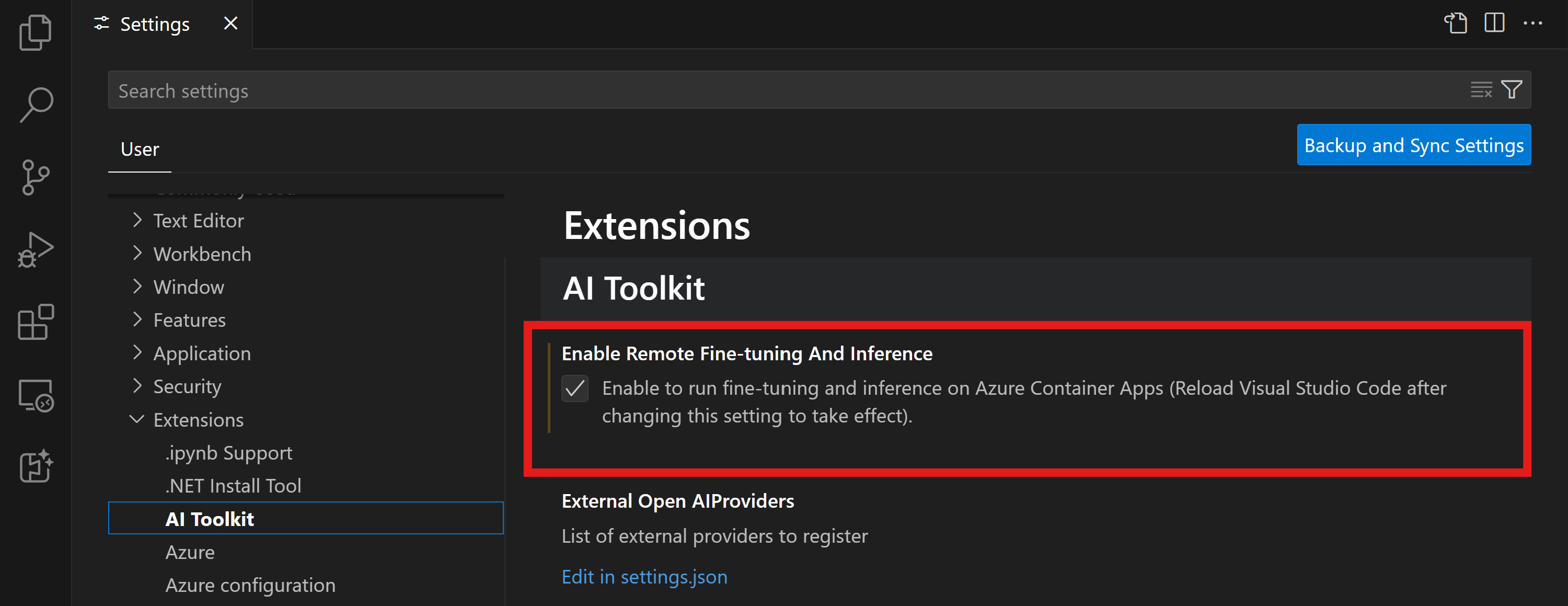
- 変更を有効にするには、VS Code を再読み込みします。
ファインチューニング プロジェクトのスキャフォールディング
- コマンド パレットで
AI Toolkit: Focus on Tools Viewを実行します (コマンド パレット (⇧⌘P (Windows、Linux Ctrl+Shift+P))) ファインチューニングに移動して、モデル カタログにアクセスします。ファインチューニングするモデルを選択します。プロジェクトに名前を付け、マシン上の場所を選択します。次に、"プロジェクトの構成" ボタンをクリックします。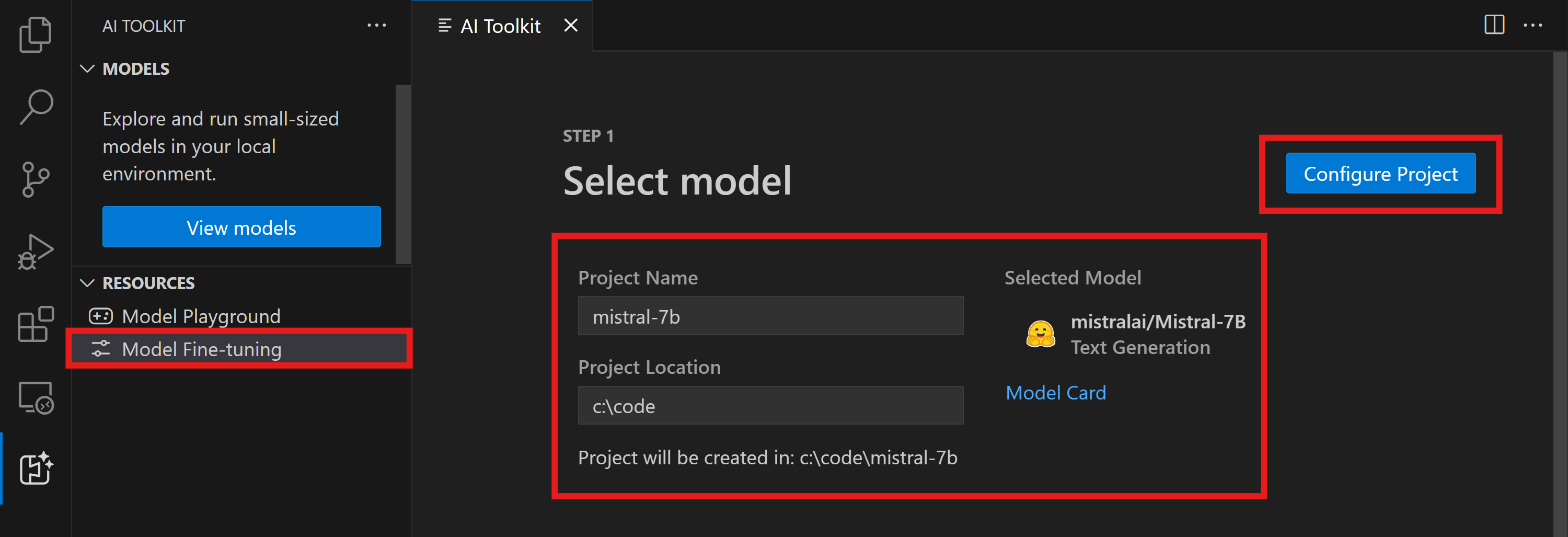
- プロジェクトの構成
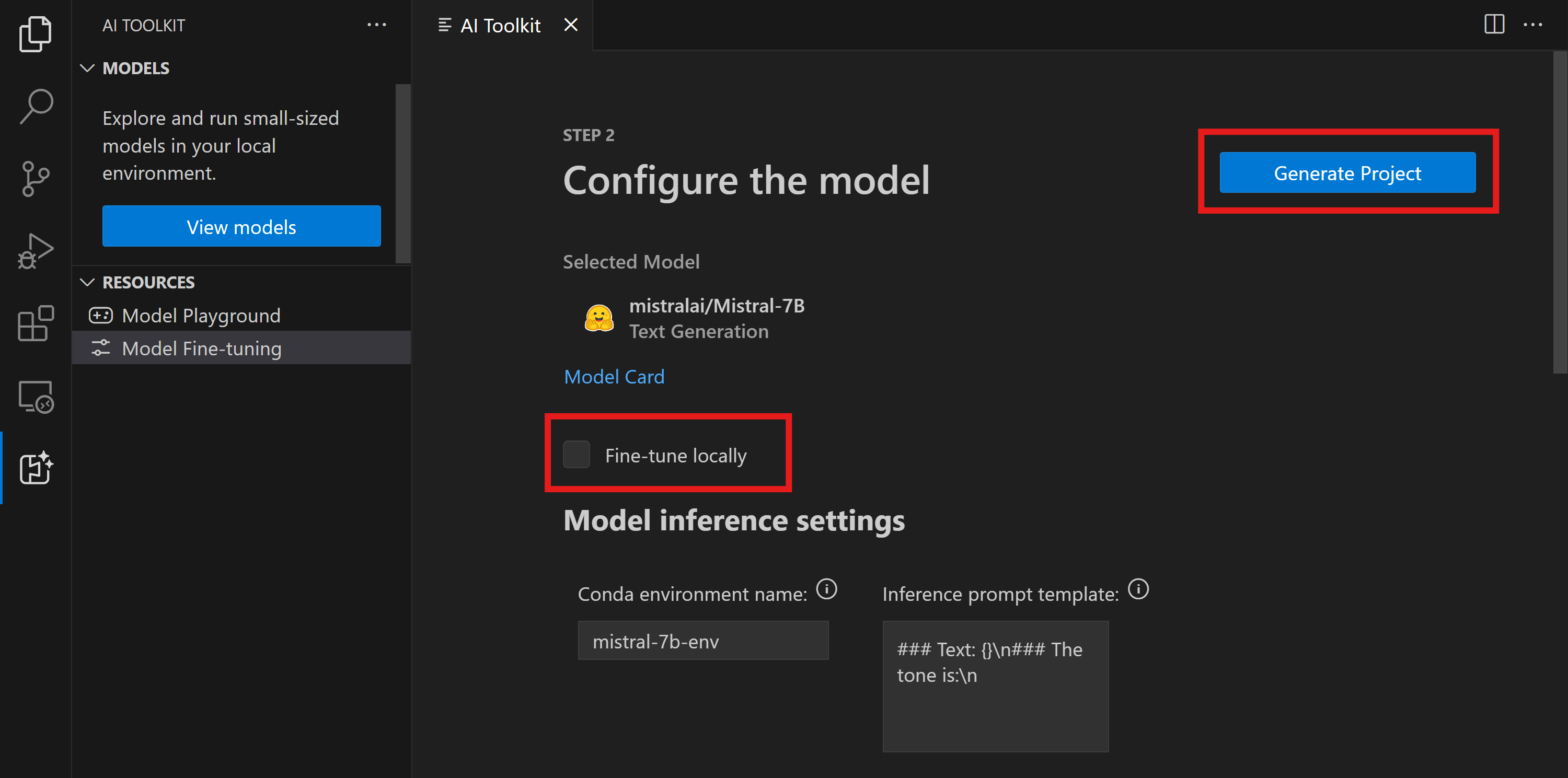
- "ローカルでファインチューニング" オプションを有効にしないでください。
- Olive の構成設定が表示され、事前設定された既定値が含まれています。必要に応じてこれらの構成を調整して入力してください。
- プロジェクトの生成 に進みます。このステージでは WSL を利用し、新しい Conda 環境のセットアップが含まれ、Dev Containers を含む将来の更新の準備が整います。
- "ワークスペースでウィンドウを再起動" を選択して、ファインチューニング プロジェクトを開きます。
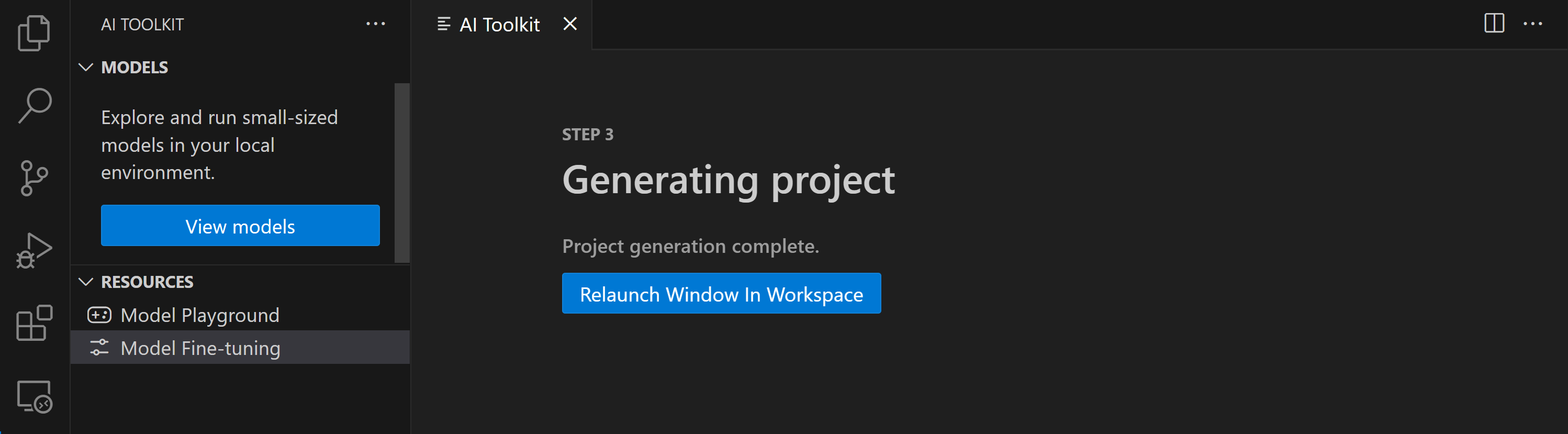
このプロジェクトは現在、VS Code 用 AI Toolkit 内でローカルまたはリモートで動作します。プロジェクト作成中に "ローカルでファインチューニング" を選択した場合、クラウド リソースなしで WSL でのみ実行されます。それ以外の場合、プロジェクトはリモート Azure Container App 環境で実行されるように制限されます。
Azure リソースのプロビジョニング
開始するには、リモート ファインチューニング用の Azure リソースをプロビジョニングする必要があります。コマンド パレットから AI Toolkit: Provision Azure Container Apps job for fine-tuning を検索して実行します。このプロセス中に、Azure サブスクリプションとリソース グループを選択するように求められます。
表示されたリンクをアウトプット チャネルで確認して、プロビジョニングの進捗状況を監視します。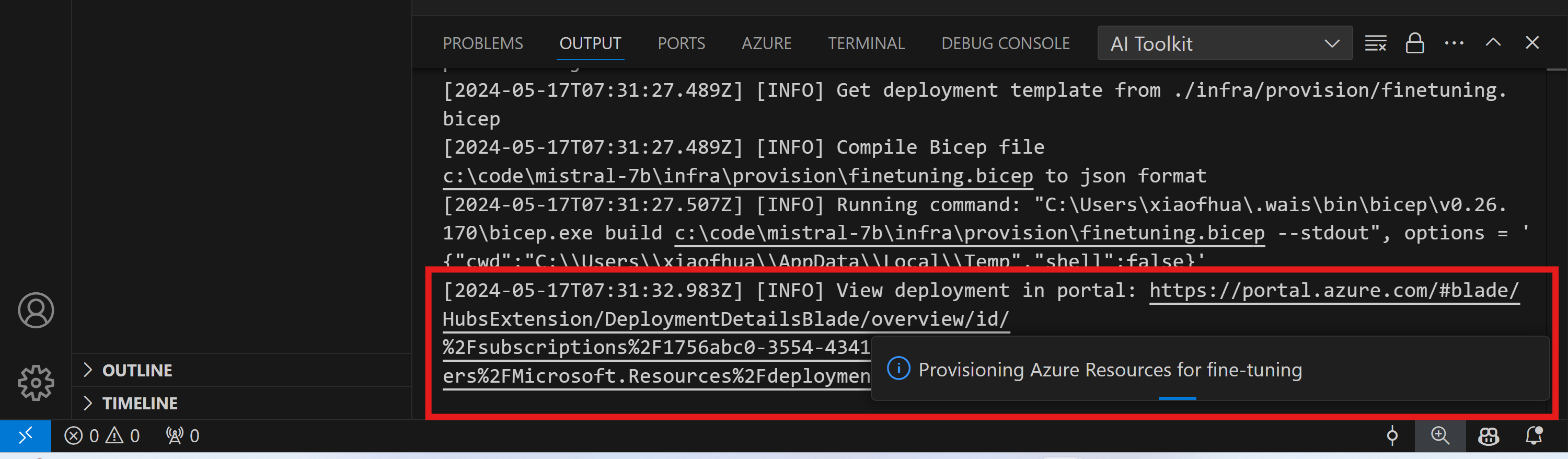
ファインチューニングの実行
リモート ファインチューニング ジョブを開始するには、コマンド パレットで AI Toolkit: Run fine-tuning コマンドを実行します。

拡張機能は、以下の操作を実行します。
-
ワークスペースを Azure Files と同期します。
-
./infra/fintuning.config.jsonで指定されたコマンドを使用して Azure Container App ジョブをトリガーします。
QLoRA がファインチューニングに使用され、ファインチューニング プロセスで推論中にモデルが使用する LoRA アダプターが作成されます。
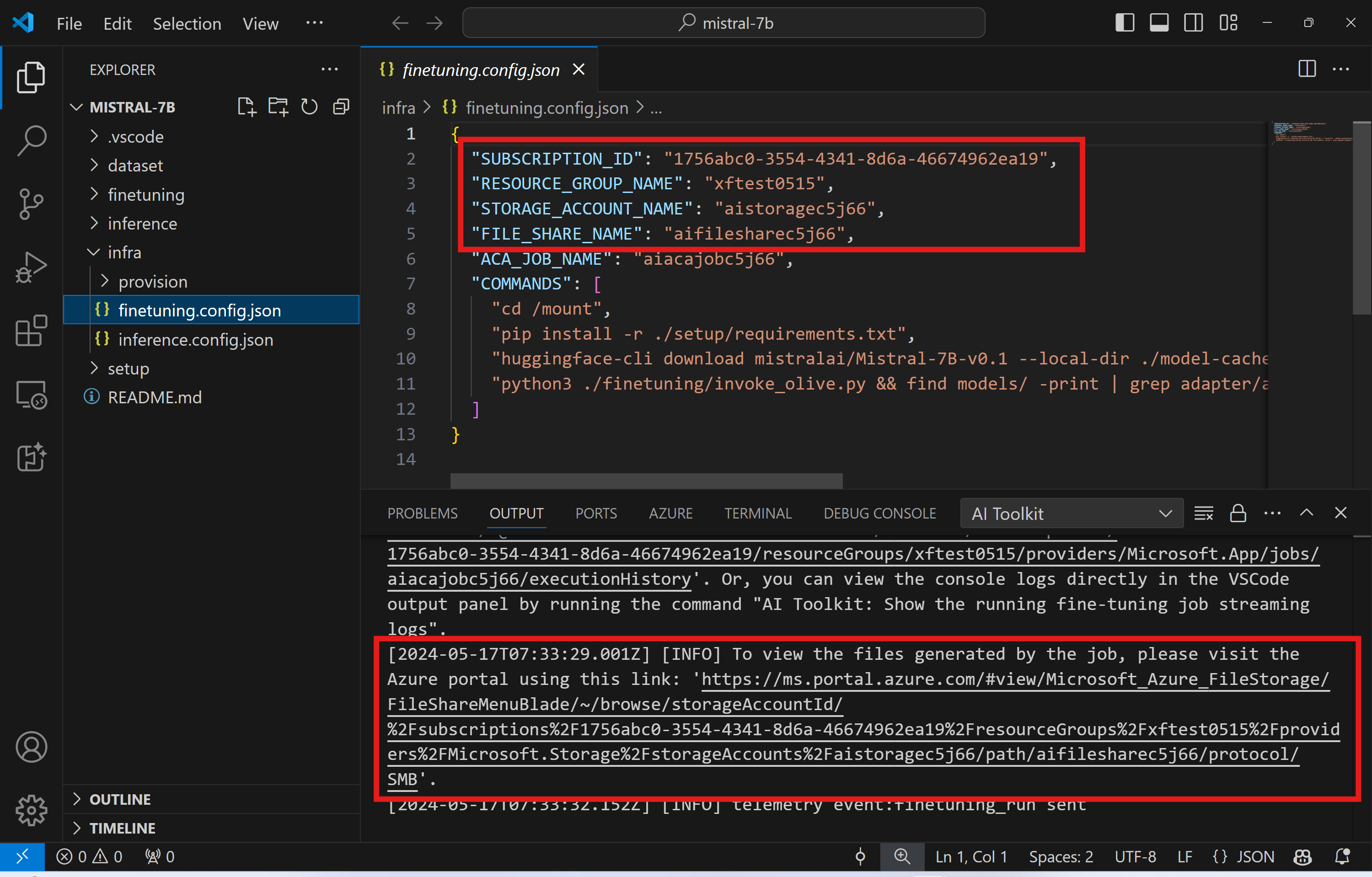
ファインチューニングの結果は Azure Files に保存されます。Azure File Share の出力ファイルを探索するには、アウトプット パネルで提供されるリンクを使用して Azure portal に移動できます。または、Azure portal に直接アクセスし、./infra/fintuning.config.json で定義されている STORAGE_ACCOUNT_NAME という名前のストレージ アカウントと、./infra/fintuning.config.json で定義されている FILE_SHARE_NAME という名前のファイル共有を見つけることができます。
ログの表示
ファインチューニング ジョブが開始されたら、Azure portal にアクセスして、システムおよびコンソール ログにアクセスできます。
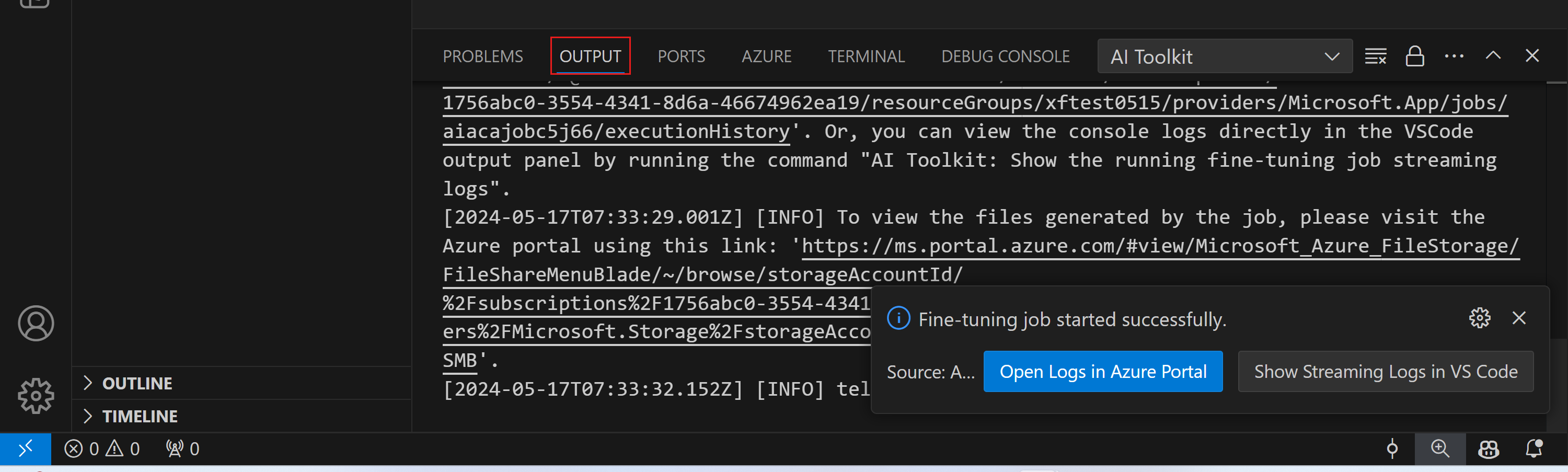
または、VSCode のアウトプット パネルでコンソール ログを直接表示することもできます。
ジョブの開始には数分かかる場合があります。既に実行中のジョブがある場合、現在のジョブは後で開始するようにキューに入れられる可能性があります。
Azure 上のログの表示とクエリ
ファインチューニング ジョブがトリガーされた後、VSCode の通知に表示される「Azure Portal でログを開く」ボタンを選択することで、Azure 上のログを表示できます。
または、既に Azure Portal を開いている場合は、Azure Container Apps ジョブの「実行履歴」パネルからジョブ履歴を見つけてください。
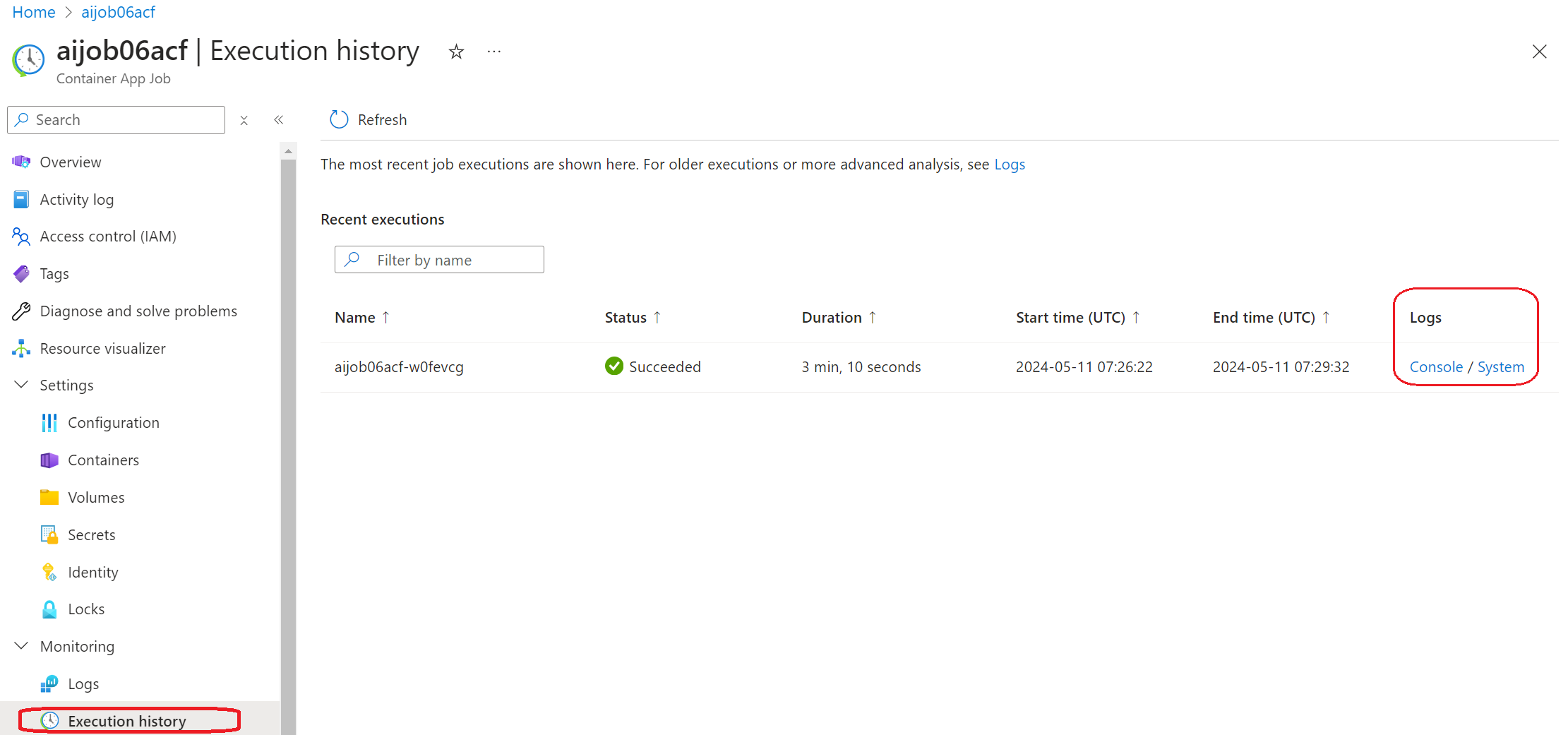
ログには、「コンソール」と「システム」の 2 種類があります。
- コンソール ログは、
stderrおよびstdoutメッセージを含む、アプリケーションからのメッセージです。これは、ストリーミング ログ セクションで既に表示されているものです。 - システム ログは、サービスレベルのイベントのステータスを含む、Azure Container Apps サービスからのメッセージです。
ログを表示およびクエリするには、「コンソール」ボタンを選択し、Log Analytics ページに移動して、すべてのログを表示し、クエリを記述できます。
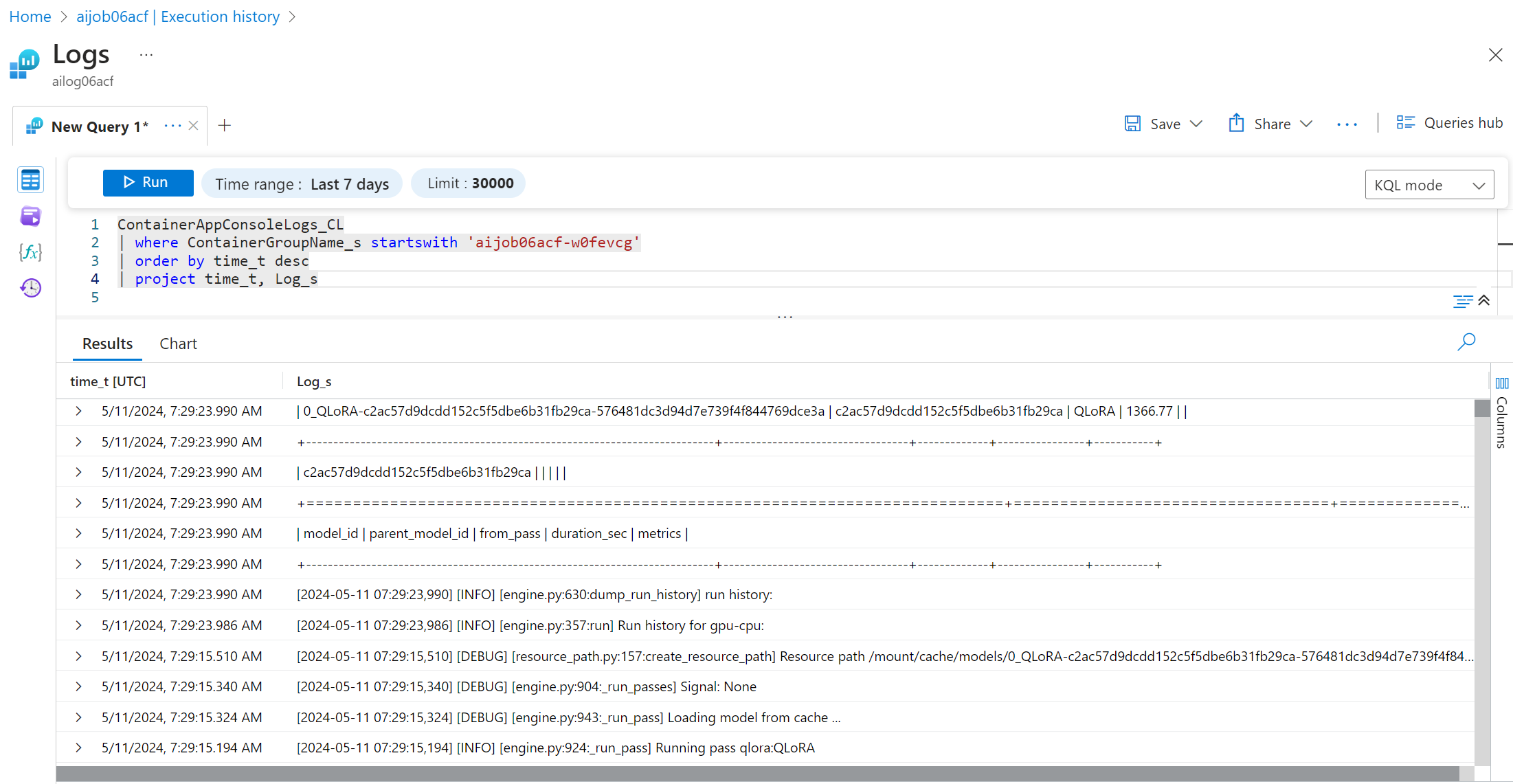
Azure Container Apps のログの詳細については、Azure Container Apps のアプリケーション ロギングを参照してください。
VSCode でストリーミング ログを表示する
ファインチューニング ジョブを開始した後、VSCode の通知に表示される「Show Streaming Logs in VS Code」ボタンを選択して、Azure 上のログを表示することもできます。
または、コマンド パレットで AI Toolkit: Show the running fine-tuning job streaming logs コマンドを実行することもできます。

実行中のファインチューニング ジョブのストリーミング ログは、アウトプット パネルに表示されます。
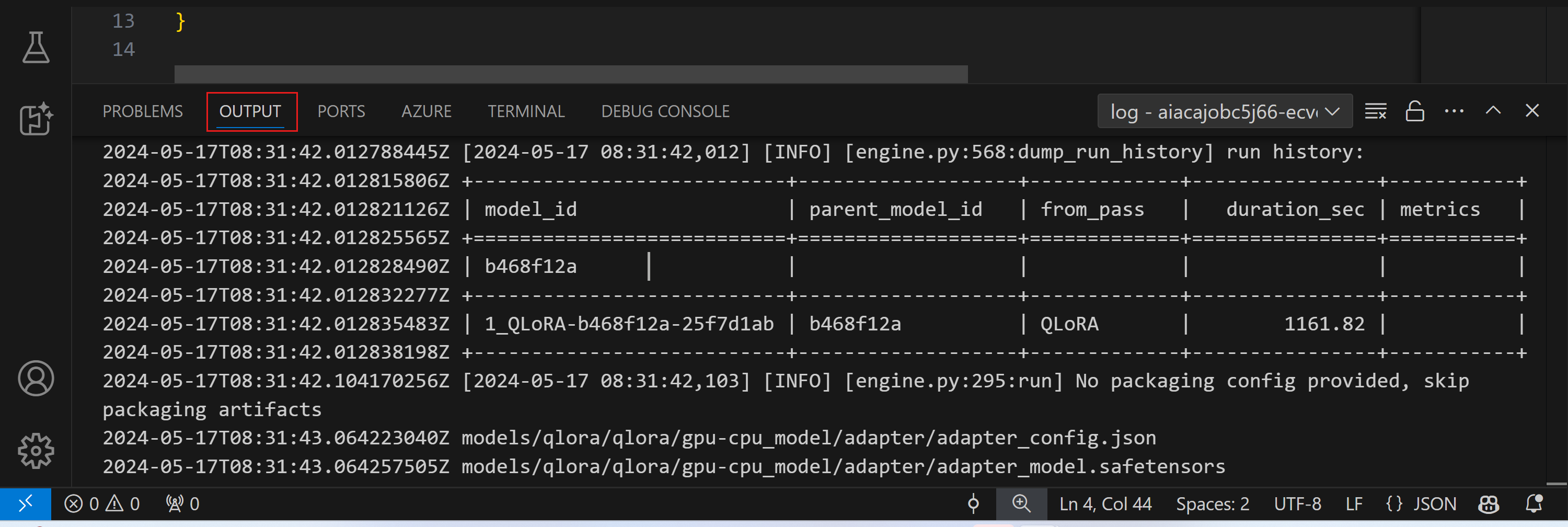
リソース不足によりジョブがキューに入れられる場合があります。ログが表示されない場合は、しばらく待ってから、ストリーミング ログに再接続するためのコマンドを実行してください。ストリーミング ログはタイムアウトして切断される可能性があります。ただし、コマンドを再度実行することで再接続できます。
ファインチューニングされたモデルでの推論
アダプターがリモート環境でトレーニングされたら、簡単な Gradio アプリケーションを使用してモデルと対話します。
Azure リソースのプロビジョニング
ファインチューニング プロセスと同様に、コマンド パレットから AI Toolkit: Provision Azure Container Apps for inference を実行して、リモート推論用の Azure リソースをセットアップする必要があります。このセットアップ中に、Azure サブスクリプションとリソース グループを選択するように求められます。

既定では、推論のサブスクリプションとリソース グループは、ファインチューニングに使用されたものと同じである必要があります。推論は同じ Azure Container App 環境を使用し、ファインチューニング ステップ中に生成された Azure Files に格納されているモデルとモデル アダプターにアクセスします。
推論のためのデプロイ
推論コードを修正したい場合、または推論モデルをリロードしたい場合は、AI Toolkit: Deploy for inference コマンドを実行してください。これにより、最新のコードが ACA と同期され、レプリカが再起動されます。

デプロイが正常に完了した後、モデルはエンドポイントを使用して評価できるようになります。VSCode の通知に表示される「Go to Inference Endpoint」ボタンを選択することで、推論 API にアクセスできます。または、Web API エンドポイントは ./infra/inference.config.json の ACA_APP_ENDPOINT の下、およびアウトプット パネルで見つけることができます。
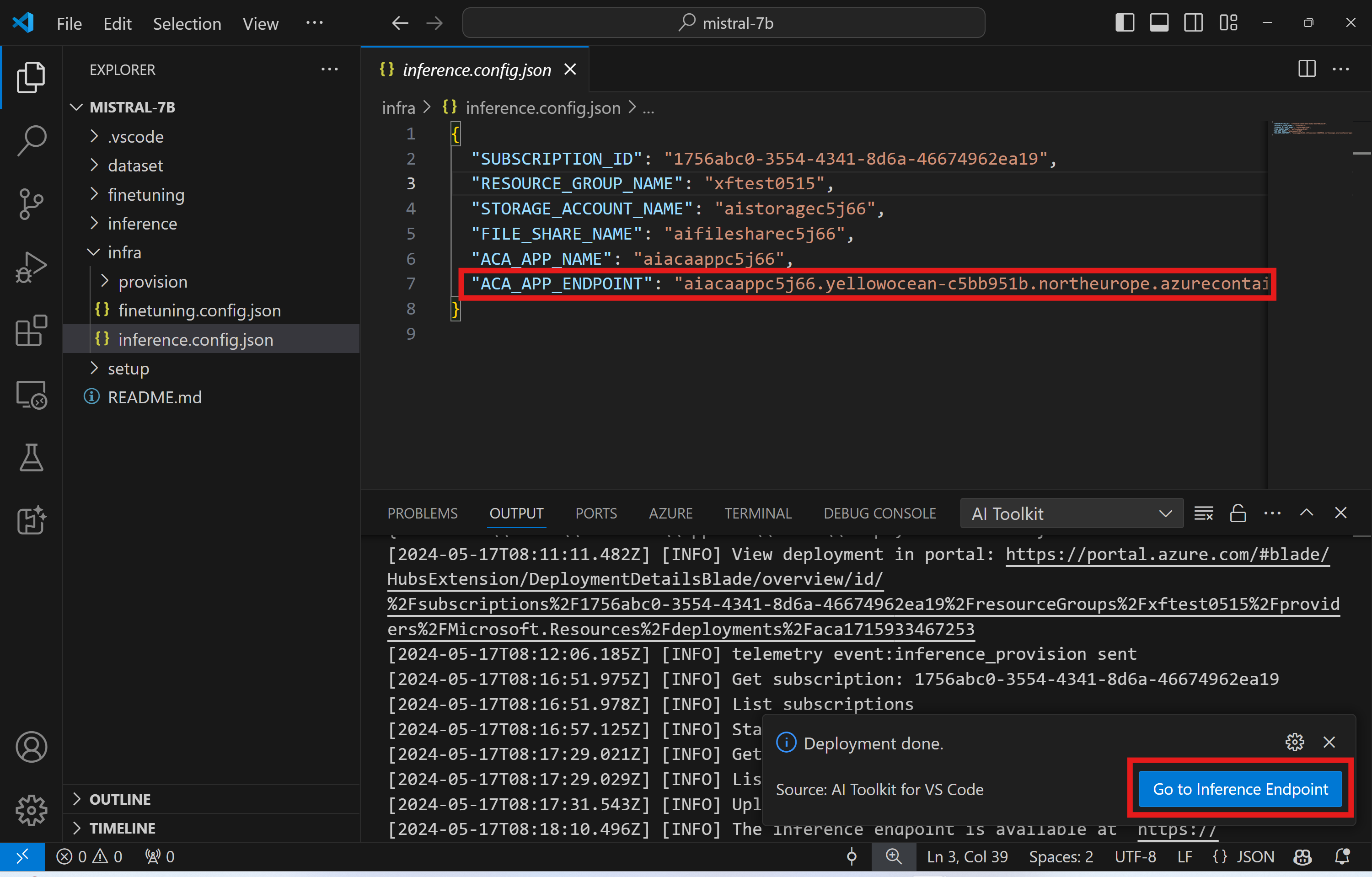
推論エンドポイントが完全に動作するようになるまで数分かかる場合があります。
高度な使用方法
ファインチューニング プロジェクトのコンポーネント
| フォルダー | 内容 |
|---|---|
infra |
リモート操作に必要なすべての構成が含まれています。 |
infra/provision/finetuning.parameters.json |
ファインチューニング用の Azure リソースをプロビジョニングするために使用される、bicep テンプレートのパラメーターが含まれています。 |
infra/provision/finetuning.bicep |
ファインチューニング用の Azure リソースをプロビジョニングするためのテンプレートが含まれています。 |
infra/finetuning.config.json |
AI Toolkit: Provision Azure Container Apps job for fine-tuning コマンドによって生成される構成ファイルです。他のリモート コマンド パレットの入力として使用されます。 |
Azure Container Apps でのファインチューニングのためのシークレットの構成
Azure Container App Secrets は、HuggingFace トークンや Weights & Biases API キーのような機密データを Azure Container Apps 内に安全に保存および管理するための方法です。AI Toolkit のコマンド パレットを使用して、プロビジョニングされた Azure container app ジョブ (./finetuning.config.json に保存されている) にシークレットを入力できます。これらのシークレットは、すべてのコンテナーで 環境変数 として設定されます。
手順
-
コマンド パレットで、
AI Toolkit: Add Azure Container Apps Job secret for fine-tuningと入力して選択します。
-
シークレットの名前と値を入力します。


たとえば、プライベート HuggingFace データセットまたは Hugging Face アクセス制御が必要なモデルを使用している場合、Hugging Face Hub で手動ログインする必要がないように、HuggingFace トークンを環境変数
HF_TOKENとして設定します。
シークレットを設定した後、Azure Container App で使用できるようになります。シークレットは、コンテナ アプリの環境変数として設定されます。
ファインチューニングのための Azure リソース プロビジョニングの構成
このガイドでは、AI Toolkit: Provision Azure Container Apps job for fine-tuning コマンドを構成する方法を説明します。
構成パラメーターは ./infra/provision/finetuning.parameters.json ファイルで見つけることができます。詳細は以下のとおりです。
| パラメーター | 説明 |
|---|---|
defaultCommands |
これは、ファインチューニング ジョブを開始するための既定のコマンドです。./infra/finetuning.config.json で上書きできます。 |
maximumInstanceCount |
このパラメーターは、GPU インスタンスの最大容量を設定します。 |
timeout |
Azure Container App ファインチューニング ジョブのタイムアウトを秒単位で設定します。既定値は 10800 (3 時間) です。Azure Container App ジョブがこのタイムアウトに達すると、ファインチューニング プロセスは停止します。ただし、チェックポイントは既定で保存されるため、ジョブが再度実行された場合、最初からやり直すのではなく、最後のチェックポイントからファインチューニング プロセスを再開できます。 |
location |
Azure リソースがプロビジョニングされる場所です。既定値は、選択したリソース グループの場所と同じです。 |
storageAccountName, fileShareName acaEnvironmentName, acaEnvironmentStorageName, acaJobName, acaLogAnalyticsName |
これらのパラメーターは、プロビジョニング用の Azure リソースの名前付けに使用されます。新しい未使用のリソース名を入力して独自のカスタム名のリソースを作成することも、既存の Azure リソースの名前を入力してそれを使用することもできます。 |
既存の Azure リソースの使用
ファインチューニング用に構成する必要のある既存の Azure リソースがある場合は、./infra/provision/finetuning.parameters.json ファイルにその名前を指定し、コマンド パレットから AI Toolkit: Provision Azure Container Apps job for fine-tuning を実行します。これにより、指定したリソースが更新され、不足しているリソースが作成されます。
たとえば、既存の Azure コンテナー環境がある場合、./infra/finetuning.parameters.json は次のようになります。
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
...
"acaEnvironmentName": {
"value": "<your-aca-env-name>"
},
"acaEnvironmentStorageName": {
"value": null
},
...
}
}
手動プロビジョニング
Azure リソースを手動でセットアップしたい場合は、./infra/provision フォルダーにある bicep ファイルを使用できます。AI Toolkit コマンド パレットを使用せずにすべての Azure リソースをセットアップおよび構成済みの場合は、finetune.config.json ファイルにリソース名を単純に入力するだけです。
例えば
{
"SUBSCRIPTION_ID": "<your-subscription-id>",
"RESOURCE_GROUP_NAME": "<your-resource-group-name>",
"STORAGE_ACCOUNT_NAME": "<your-storage-account-name>",
"FILE_SHARE_NAME": "<your-file-share-name>",
"ACA_JOB_NAME": "<your-aca-job-name>",
"COMMANDS": [
"cd /mount",
"pip install huggingface-hub==0.22.2",
"huggingface-cli download <your-model-name> --local-dir ./model-cache/<your-model-name> --local-dir-use-symlinks False",
"pip install -r ./setup/requirements.txt",
"python3 ./finetuning/invoke_olive.py && find models/ -print | grep adapter/adapter"
]
}
テンプレートに含まれる推論コンポーネント
| フォルダー | 内容 |
|---|---|
infra |
リモート操作に必要なすべての構成が含まれています。 |
infra/provision/inference.parameters.json |
推論用の Azure リソースをプロビジョニングするために使用される、bicep テンプレートのパラメーターが含まれています。 |
infra/provision/inference.bicep |
推論用の Azure リソースをプロビジョニングするためのテンプレートが含まれています。 |
infra/inference.config.json |
AI Toolkit: Provision Azure Container Apps for inference コマンドによって生成される構成ファイルです。他のリモート コマンド パレットの入力として使用されます。 |
Azure リソース プロビジョニングの構成
このガイドでは、AI Toolkit: Provision Azure Container Apps for inference コマンドを構成する方法を説明します。
構成パラメーターは ./infra/provision/inference.parameters.json ファイルで見つけることができます。詳細は以下のとおりです。
| パラメーター | 説明 |
|---|---|
defaultCommands |
これは、Web API を開始するためのコマンドです。 |
maximumInstanceCount |
このパラメーターは、GPU インスタンスの最大容量を設定します。 |
location |
Azure リソースがプロビジョニングされる場所です。既定値は、選択したリソース グループの場所と同じです。 |
storageAccountName, fileShareName acaEnvironmentName, acaEnvironmentStorageName, acaAppName, acaLogAnalyticsName |
これらのパラメーターは、プロビジョニング用の Azure リソースの名前付けに使用されます。既定では、これらはファインチューニング リソース名と同じになります。新しい未使用のリソース名を入力して独自のカスタム名のリソースを作成することも、既存の Azure リソースの名前を入力してそれを使用することもできます。 |
既存の Azure リソースの使用
既定では、推論プロビジョニングは、ファインチューニングに使用されたのと同じ Azure Container App 環境、ストレージ アカウント、Azure File Share、および Azure Log Analytics を使用します。推論 API 専用の個別の Azure Container App が作成されます。
ファインチューニング ステップ中に Azure リソースをカスタマイズした場合、または推論に独自の既存の Azure リソースを使用したい場合は、./infra/inference.parameters.json ファイルにその名前を指定します。次に、コマンド パレットから AI Toolkit: Provision Azure Container Apps for inference コマンドを実行します。これにより、指定されたリソースが更新され、不足しているリソースが作成されます。
たとえば、既存の Azure コンテナー環境がある場合、./infra/finetuning.parameters.json は次のようになります。
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
...
"acaEnvironmentName": {
"value": "<your-aca-env-name>"
},
"acaEnvironmentStorageName": {
"value": null
},
...
}
}
手動プロビジョニング
Azure リソースを手動で構成したい場合は、./infra/provision フォルダーにある bicep ファイルを使用できます。AI Toolkit コマンド パレットを使用せずにすべての Azure リソースをセットアップおよび構成済みの場合は、inference.config.json ファイルにリソース名を単純に入力するだけです。
例えば
{
"SUBSCRIPTION_ID": "<your-subscription-id>",
"RESOURCE_GROUP_NAME": "<your-resource-group-name>",
"STORAGE_ACCOUNT_NAME": "<your-storage-account-name>",
"FILE_SHARE_NAME": "<your-file-share-name>",
"ACA_APP_NAME": "<your-aca-name>",
"ACA_APP_ENDPOINT": "<your-aca-endpoint>"
}
学んだこと
この記事では、以下の方法を学びました。
- Azure Container Apps でのファインチューニングと推論をサポートするように VS Code 用 AI Toolkit をセットアップします。
- VS Code 用 AI Toolkit でファインチューニング プロジェクトを作成します。
- データセットの選択やトレーニング パラメーターなど、ファインチューニング ワークフローを構成します。
- ファインチューニング ワークフローを実行して、事前学習済みモデルを特定のデータセットに適応させます。
- メトリクスやログを含む、ファインチューニング プロセスの結果を表示します。
- サンプル ノートブックを使用して、モデルの推論とテストを行います。
- ファインチューニング プロジェクトをエクスポートして、他のユーザーと共有します。
- 異なるデータセットまたはトレーニング パラメーターを使用してモデルを再評価します。
- 失敗したジョブを処理し、再実行のために構成を調整します。
- サポートされているモデルと、ファインチューニングの要件を理解します。
- VS Code 用 AI Toolkit を使用して、Azure リソースのプロビジョニング、ファインチューニング ジョブの実行、推論のためのモデルのデプロイなど、ファインチューニング プロジェクトを管理します。