VS Code で Data Wrangler をクイックスタートする
Data Wrangler は、VS Code および VS Code Jupyter Notebooks に統合された、コード中心のデータ表示およびクリーニングツールです。データの表示と分析、洞察に満ちた列の統計と視覚化、データのクリーニングと変換時の Pandas コードの自動生成のための豊富なユーザーインターフェイスを提供します。
以下は、ノートブックから Data Wrangler を開いて組み込みの操作でデータを分析およびクリーニングし、自動生成されたコードをノートブックにエクスポートする例です。
このページは、Data Wrangler をすばやく起動して実行できるようにすることを目的としています。
環境をセットアップする
- まだインストールしていない場合は、Python をインストールしてください (注: Data Wrangler は Python バージョン 3.8 以降のみをサポートしています)。
- Data Wrangler 拡張機能をインストールする
Data Wrangler を初めて起動すると、接続する Python カーネルを尋ねられます。また、Pandas など、必要な Python パッケージがインストールされているかどうかもマシンと環境をチェックします。
Data Wrangler を開く
Data Wrangler を使用しているときは常に、サンドボックス化された環境にいるため、データを安全に探索および変換できます。変更を明示的にエクスポートするまで、元のデータセットは変更されません。
Jupyter Notebook から Data Wrangler を起動する
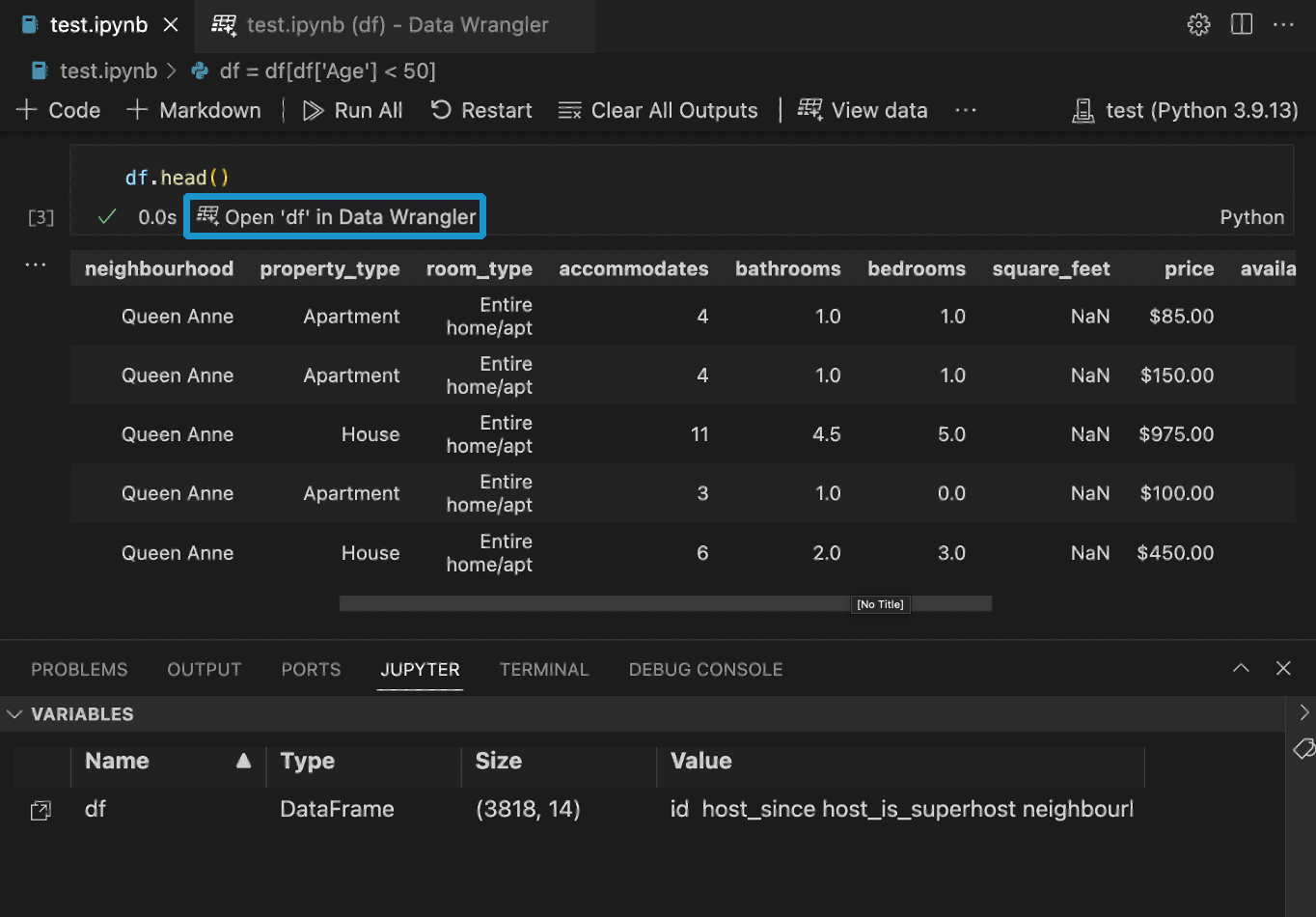
ノートブックに Pandas データフレームがある場合、df.head()、df.tail()、display(df)、print(df)、および df のいずれかを実行した後、セルの下部に [Data Wrangler で 'df' を開く] ボタン (df はデータフレームの変数名) が表示されるようになります。
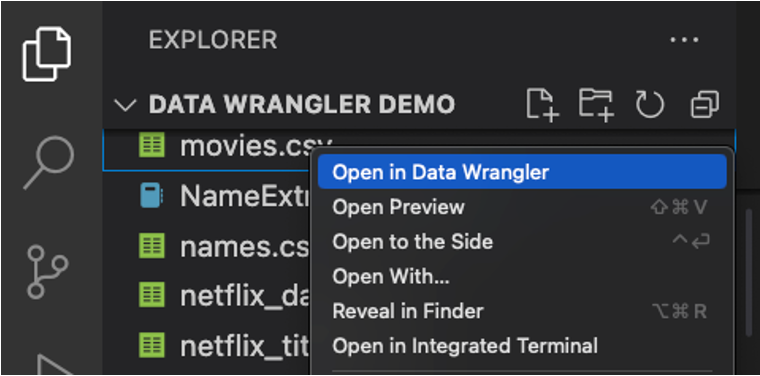
ファイルから直接 Data Wrangler を起動する
ローカルファイル (.csv など) から Data Wrangler を直接起動することもできます。これを行うには、開きたいファイルを含む任意のフォルダーを VS Code で開きます。ファイルエクスプローラービューで、ファイルを右クリックして [Data Wrangler で開く] をクリックします。
UIツアー
Data Wrangler は、データの操作時に2つのモードがあります。各モードの詳細は、以下のセクションで説明します。
- 表示モード: 表示モードは、データをすばやく表示、フィルター処理、ソートできるようにインターフェイスを最適化します。このモードは、データセットの初期探索に最適です。
- 編集モード: 編集モードは、データセットに変換、クリーニング、または変更を適用できるようにインターフェイスを最適化します。インターフェイスでこれらの変換を適用すると、Data Wrangler は関連する Pandas コードを自動的に生成し、これを再利用のためにノートブックにエクスポートできます。
注: デフォルトでは、Data Wrangler は表示モードで開きます。この動作は、設定エディター で変更できます。
表示モードのインターフェース
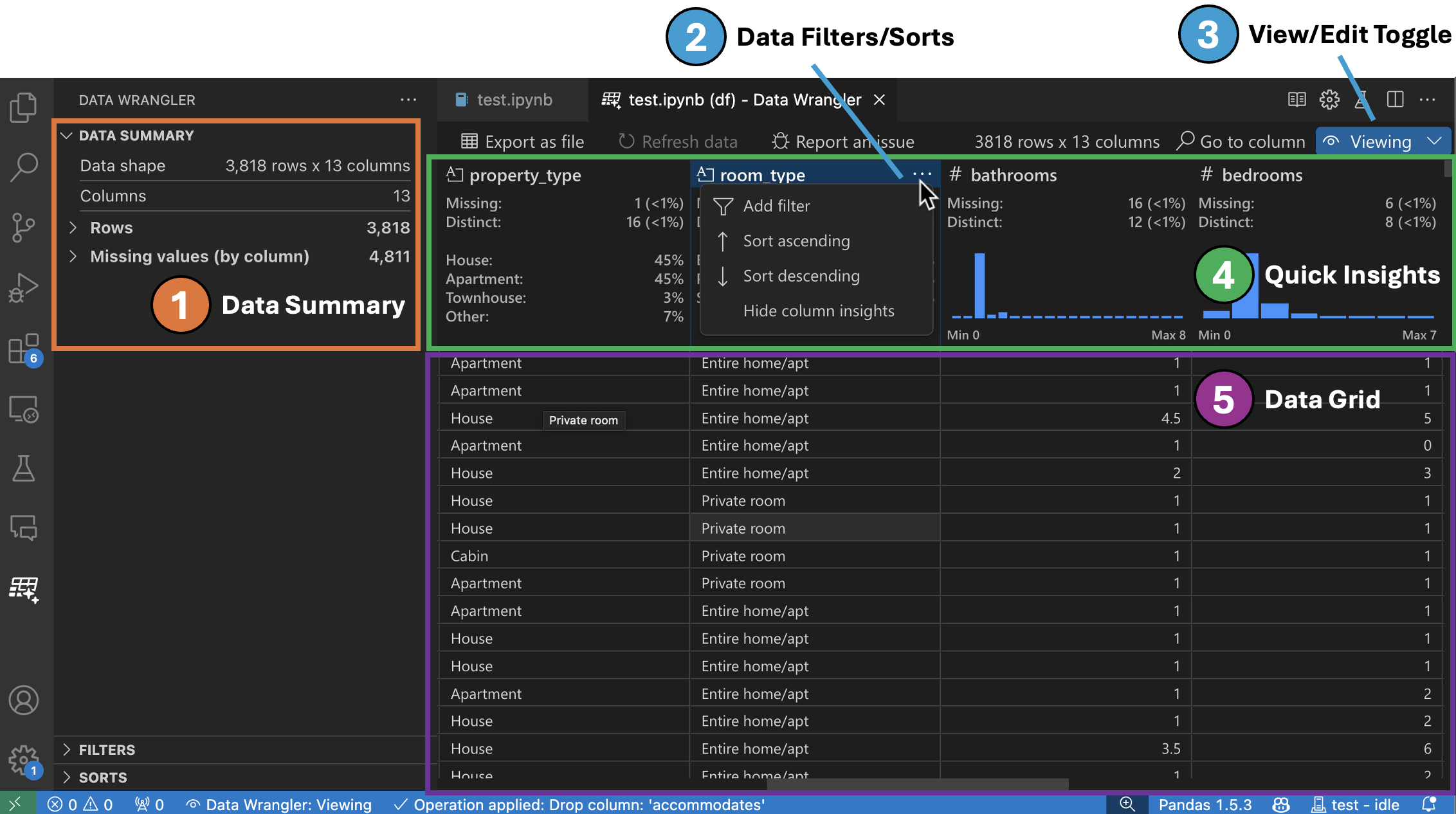
-
データ概要パネルには、データセット全体または選択された特定の列の詳細な統計が表示されます。
-
列のヘッダーメニューから、列にデータフィルター/ソートを適用できます。
-
Data Wrangler の表示モードと編集モードを切り替えて、組み込みのデータ操作にアクセスします。
-
クイックインサイトヘッダーは、各列に関する貴重な情報をすばやく確認できる場所です。列のデータ型に応じて、クイックインサイトはデータの分布またはデータポイントの頻度、および欠損値と個別値を表示します。
-
データグリッドは、データセット全体を表示できるスクロール可能なペインを提供します。
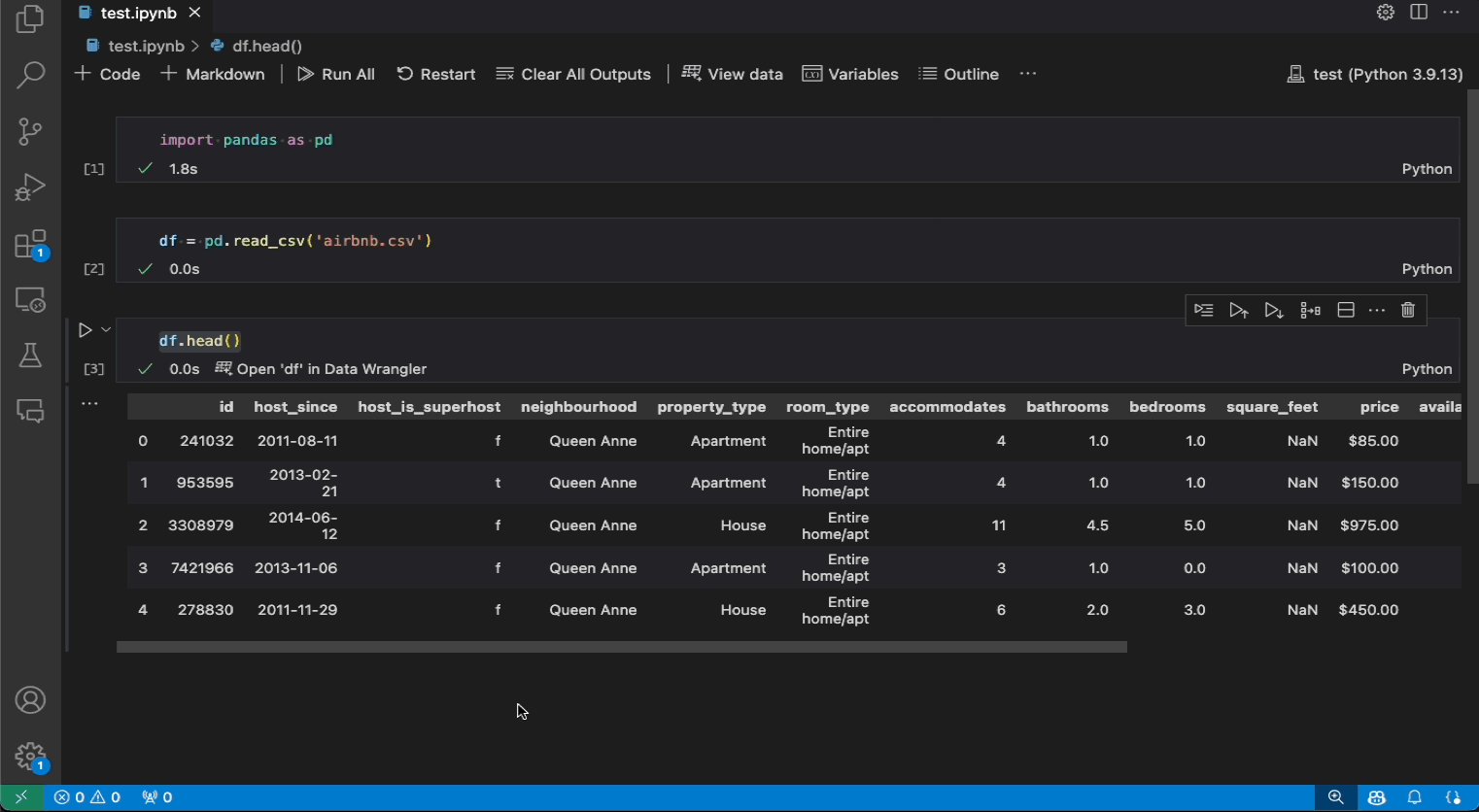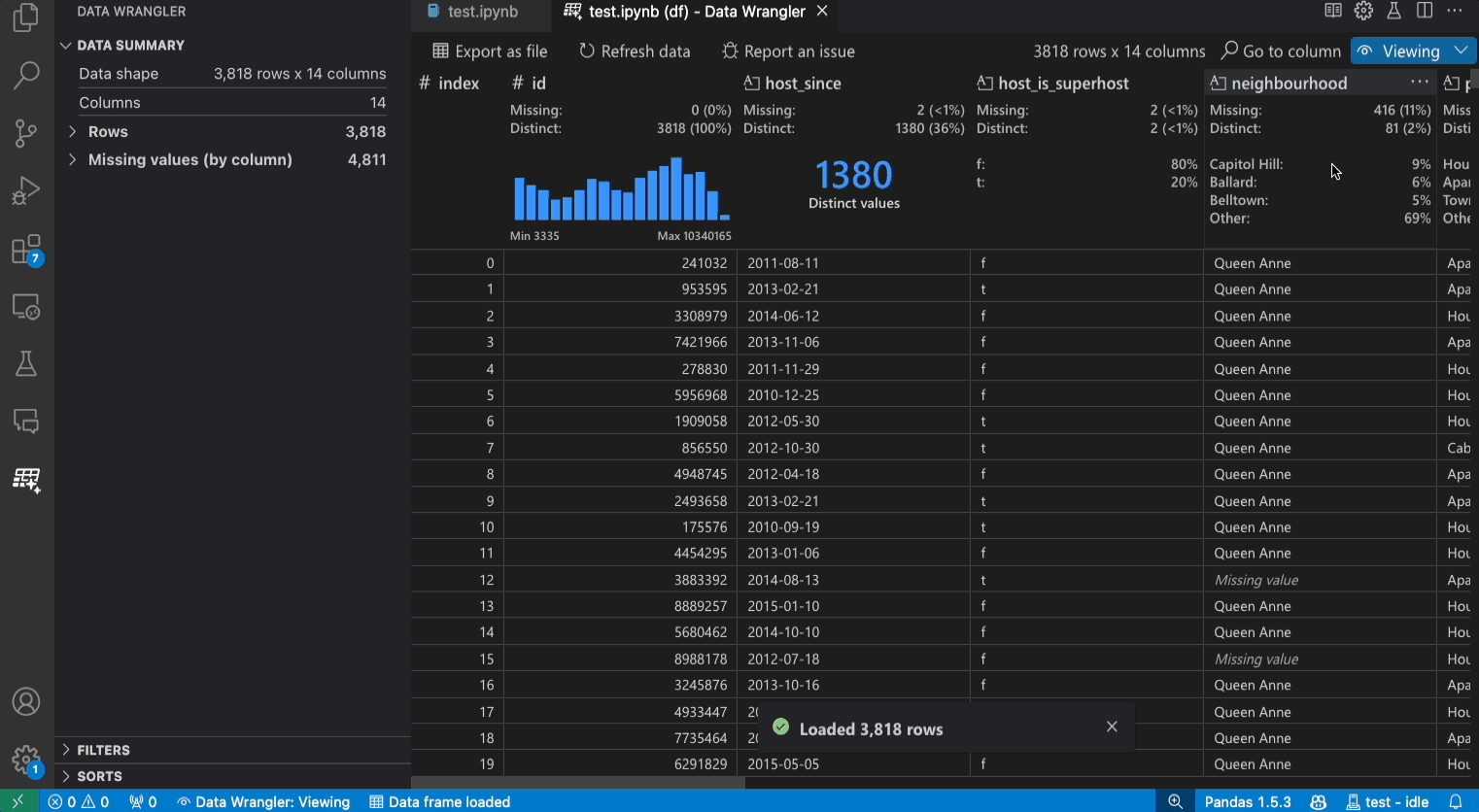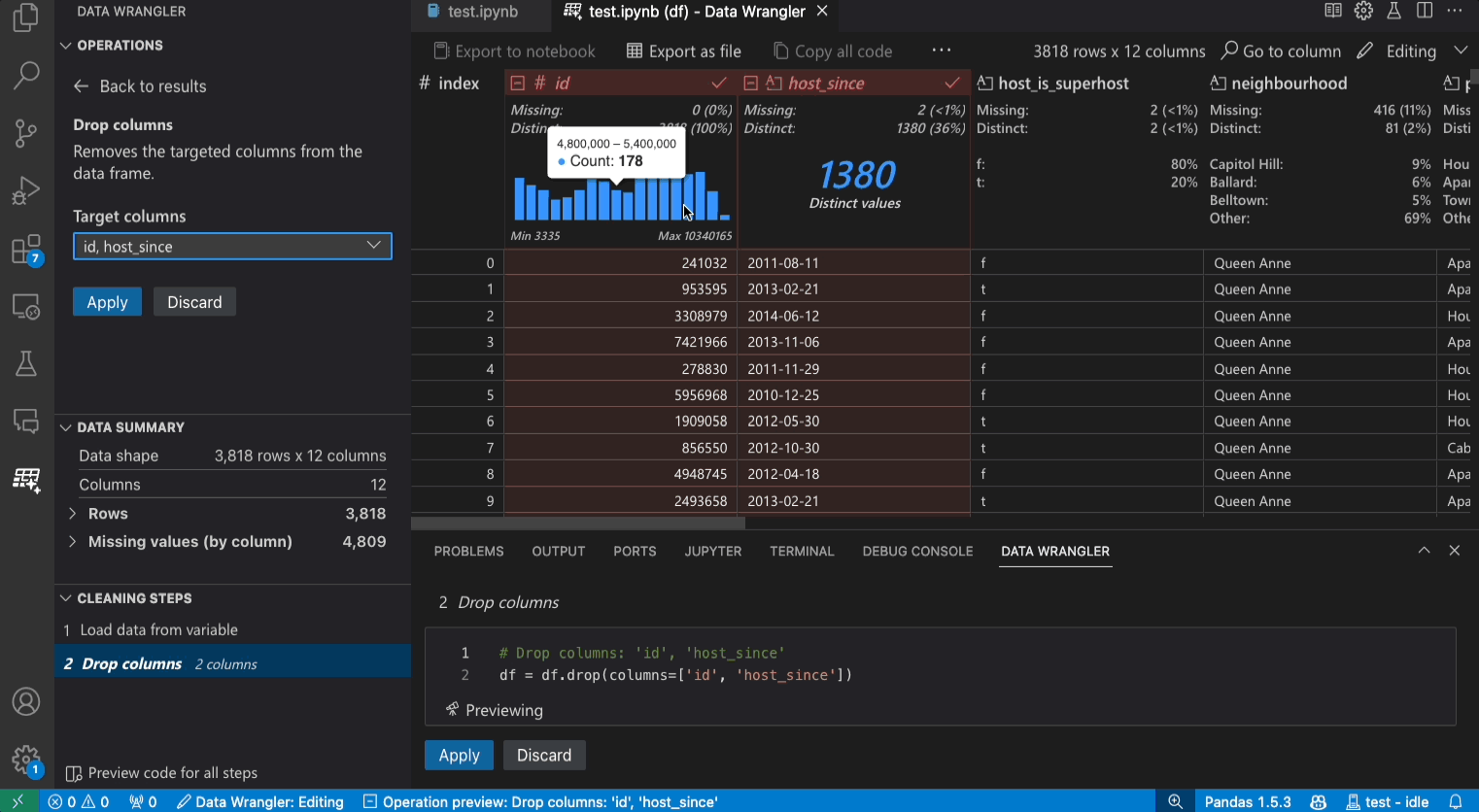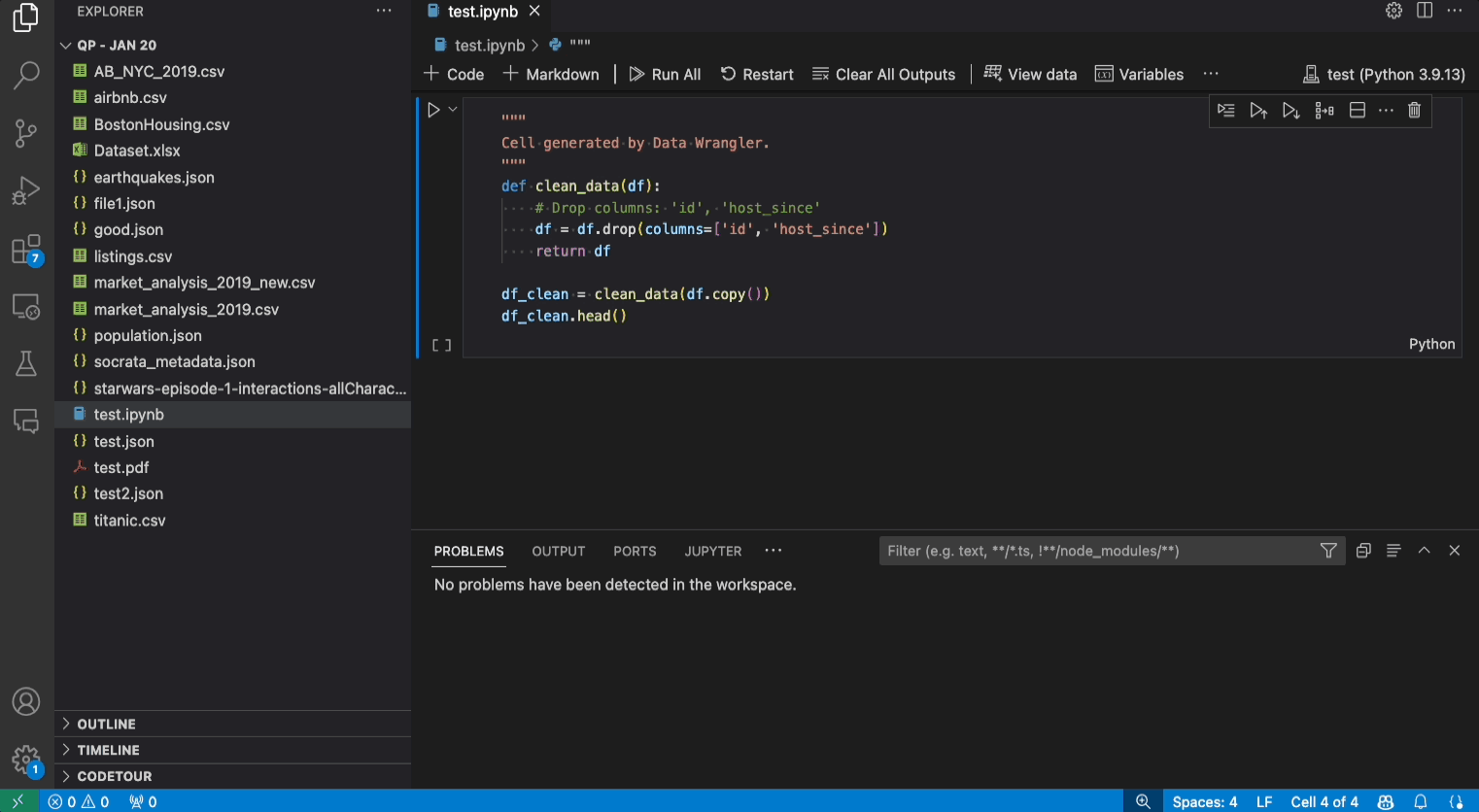
編集モードのインターフェース
編集モードに切り替えると、Data Wrangler で追加の機能とユーザーインターフェイス要素が有効になります。次のスクリーンショットでは、Data Wrangler を使用して、最後の列の欠損値をその列の中央値に置き換えています。
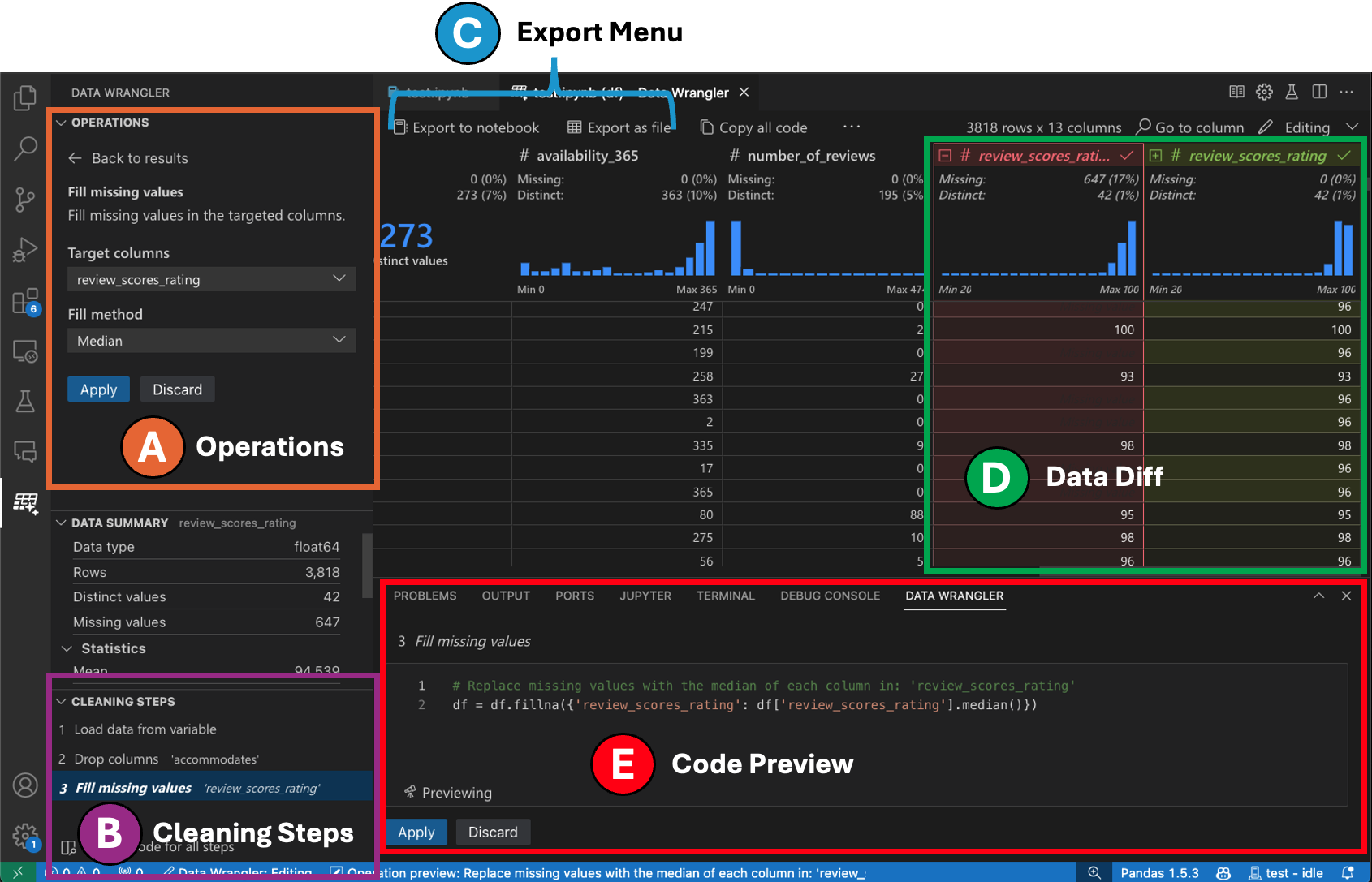
-
操作パネルでは、Data Wrangler の組み込みのデータ操作すべてを検索できます。操作はカテゴリ別に整理されています。
-
クリーニングステップパネルには、以前に適用されたすべての操作のリストが表示されます。これにより、ユーザーは特定の操作を元に戻したり、最新の操作を編集したりできます。ステップを選択すると、データグリッドで変更がハイライト表示され、その操作に関連付けられた生成されたコードが表示されます。
-
エクスポートメニューを使用すると、コードを Jupyter Notebook にエクスポートしたり、データを新しいファイルにエクスポートしたりできます。
-
操作が選択され、データへの影響をプレビューしている場合、グリッドにはデータに行った変更のデータ差分ビューがオーバーレイされます。
-
コードプレビューセクションには、操作が選択されたときに Data Wrangler が生成した Python および Pandas コードが表示されます。操作が選択されていない場合は空のままです。生成されたコードを編集すると、データグリッドでデータへの影響がハイライト表示されます。
例: データセット内の欠損値を置き換える
データセットが与えられた場合、一般的なデータクリーニングタスクの1つは、データ内の欠損値を処理することです。以下の例は、Data Wrangler を使用して列の欠損値をその列の中央値に置き換える方法を示しています。変換はインターフェイスを介して行われますが、Data Wrangler は欠損値の置き換えに必要な Python および Pandas コードも自動的に生成します。
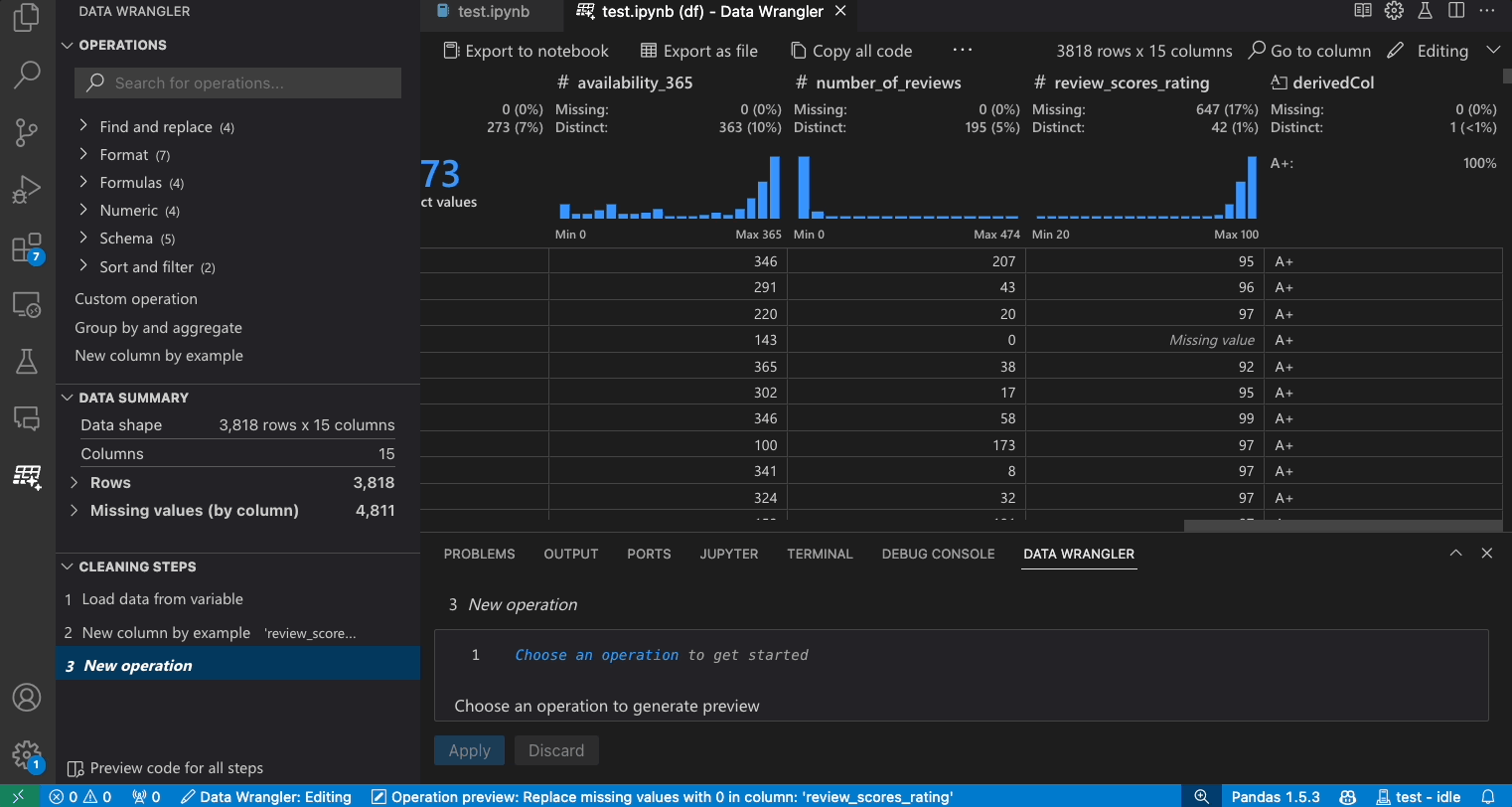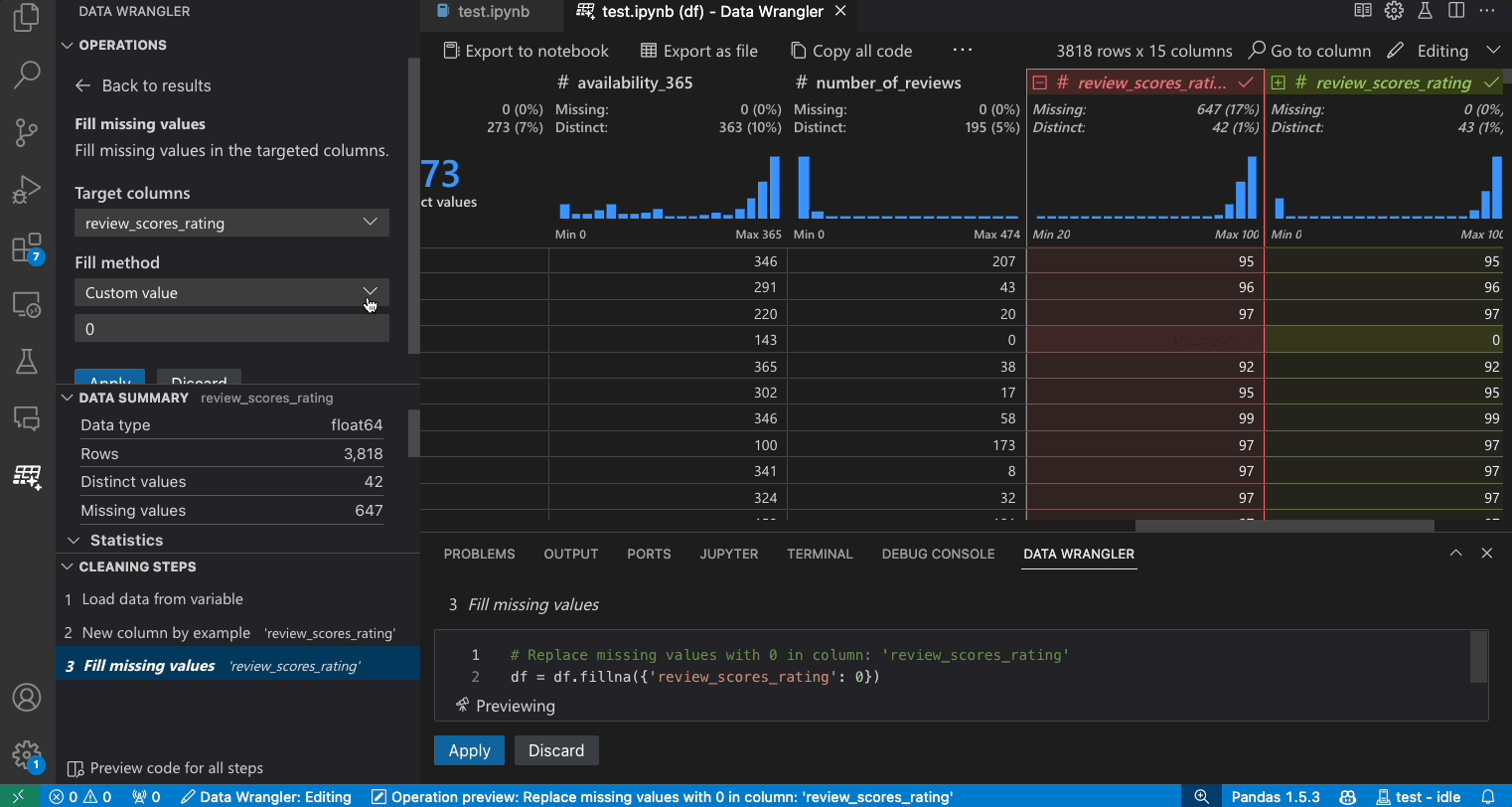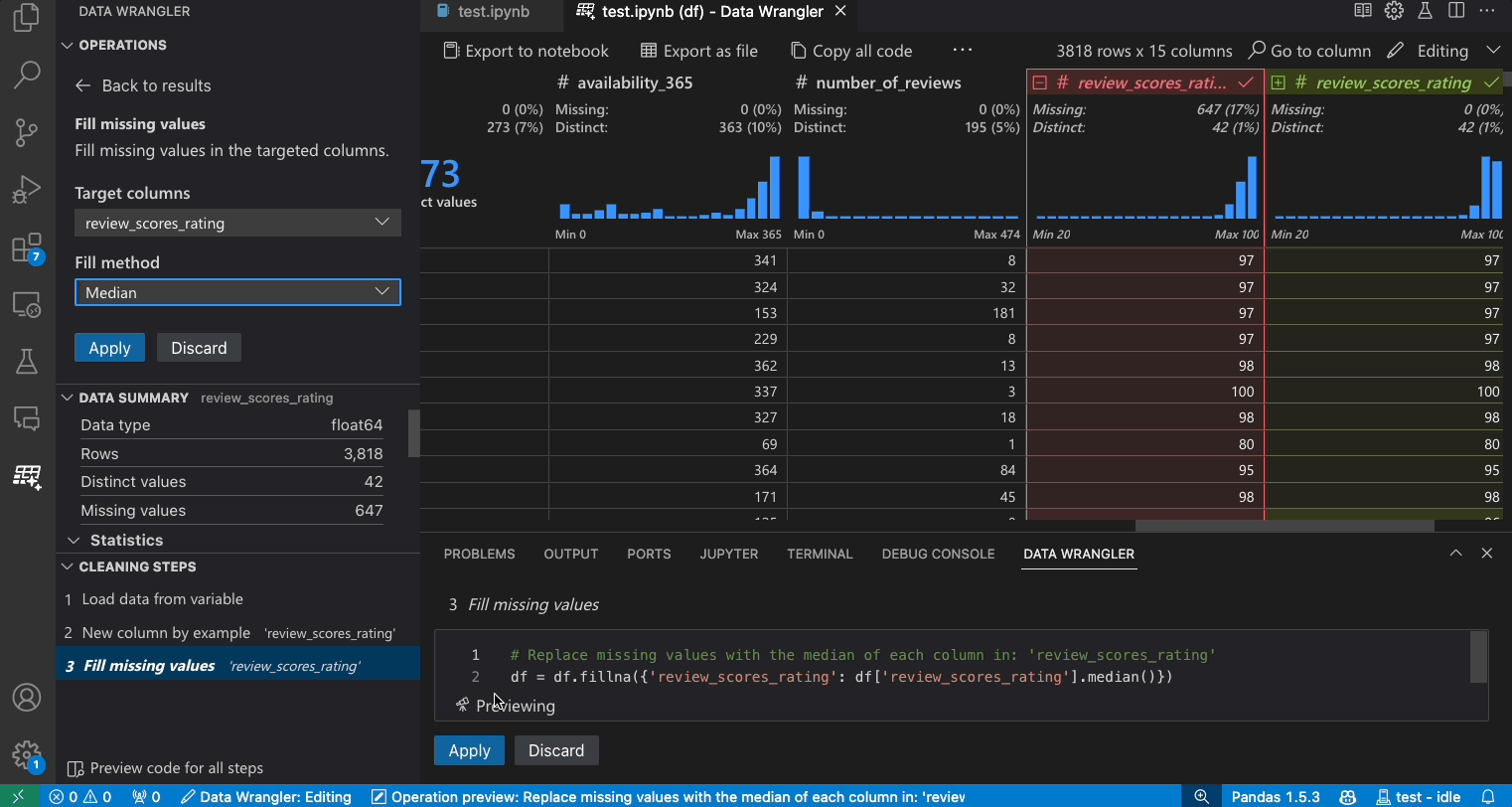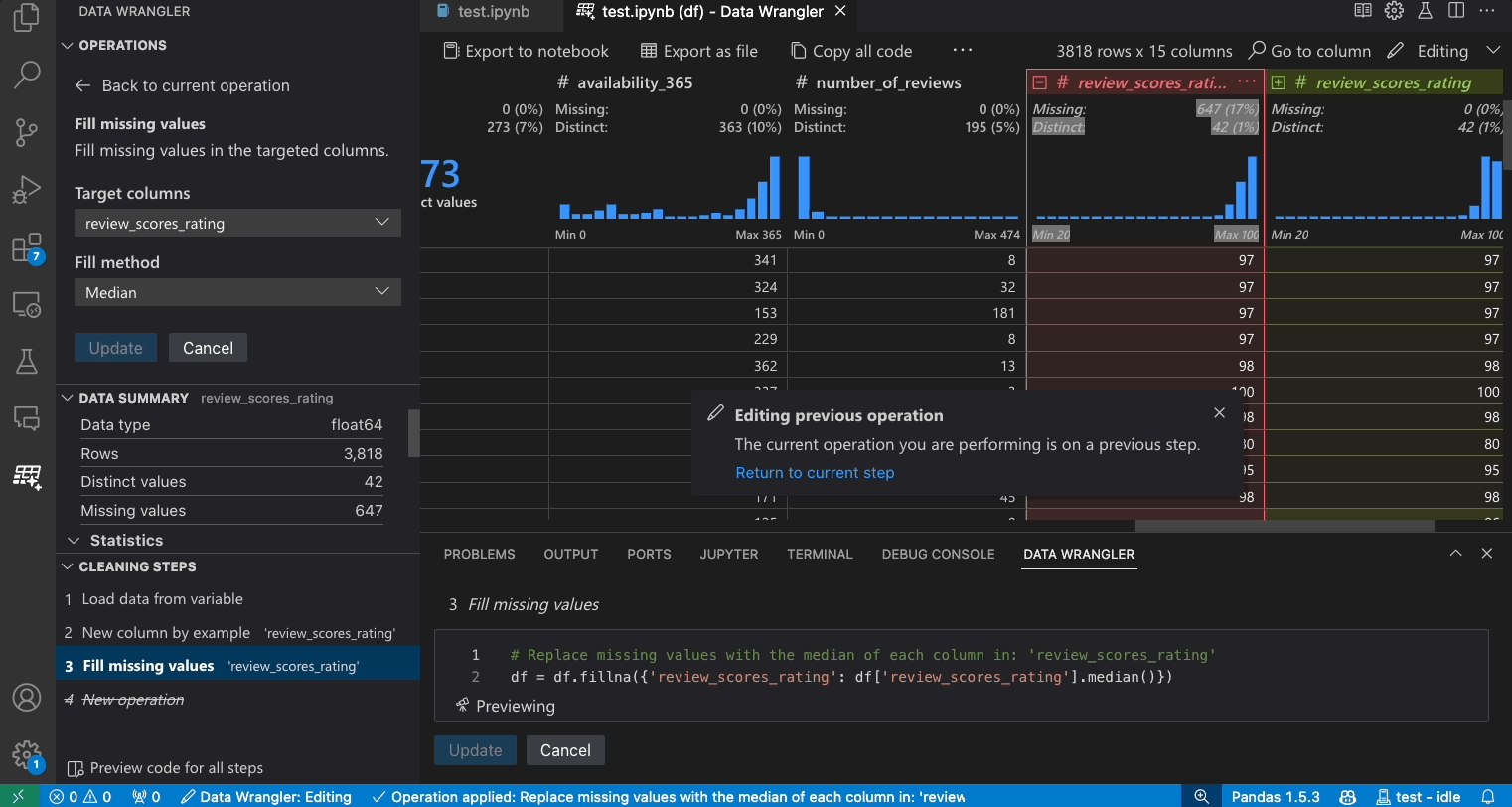
- 操作パネルで、欠損値を埋める操作を検索します。
- 欠損値を何に置き換えるかをパラメーターで指定します。この場合、欠損値を列の中央値に置き換えます。
- データグリッドがデータ差分で正しい変更を表示していることを確認します。
- Data Wrangler によって生成されたコードが意図したものであることを確認します。
- 操作を適用すると、クリーニングステップ履歴に追加されます。
次のステップ
このページでは、Data Wrangler をすばやく開始する方法を説明しました。Data Wrangler が現在サポートしているすべての組み込み操作を含む、Data Wrangler の完全なドキュメントとチュートリアルについては、次のページを参照してください。