AI Toolkit for VS Code を使用してモデルを変換する
モデル変換は、開発者や AI エンジニアがローカルの Windows プラットフォームで事前に構築された機械学習モデルを変換、量子化、最適化、評価するのに役立つように設計された統合開発環境です。Hugging Face などのソースから変換されたモデルを最適化し、NPU、GPU、CPU を搭載したローカルデバイスでの推論を可能にする、合理化されたエンドツーエンドのエクスペリエンスを提供します。
前提条件
- VS Code がインストールされている必要があります。以下の手順に従ってVS Code をセットアップしてください。
- AI Toolkit 拡張機能がインストールされている必要があります。詳細については、「AI Toolkit のインストール」を参照してください。
プロジェクトを作成する
モデル変換でプロジェクトを作成することは、機械学習モデルの変換、最適化、量子化、評価に向けた最初のステップです。
-
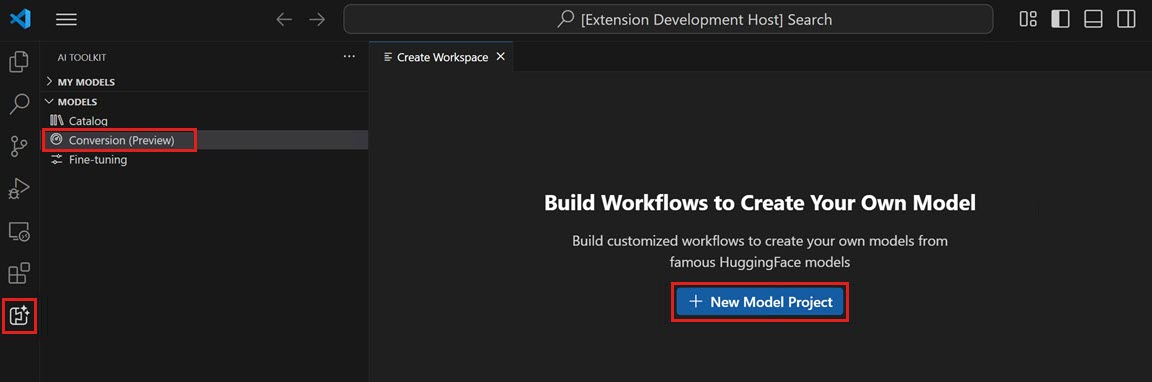
AI Toolkit ビューを開き、Models > Conversion を選択してモデル変換を起動します。
-
New Model Project を選択して新しいプロジェクトを開始します。
-
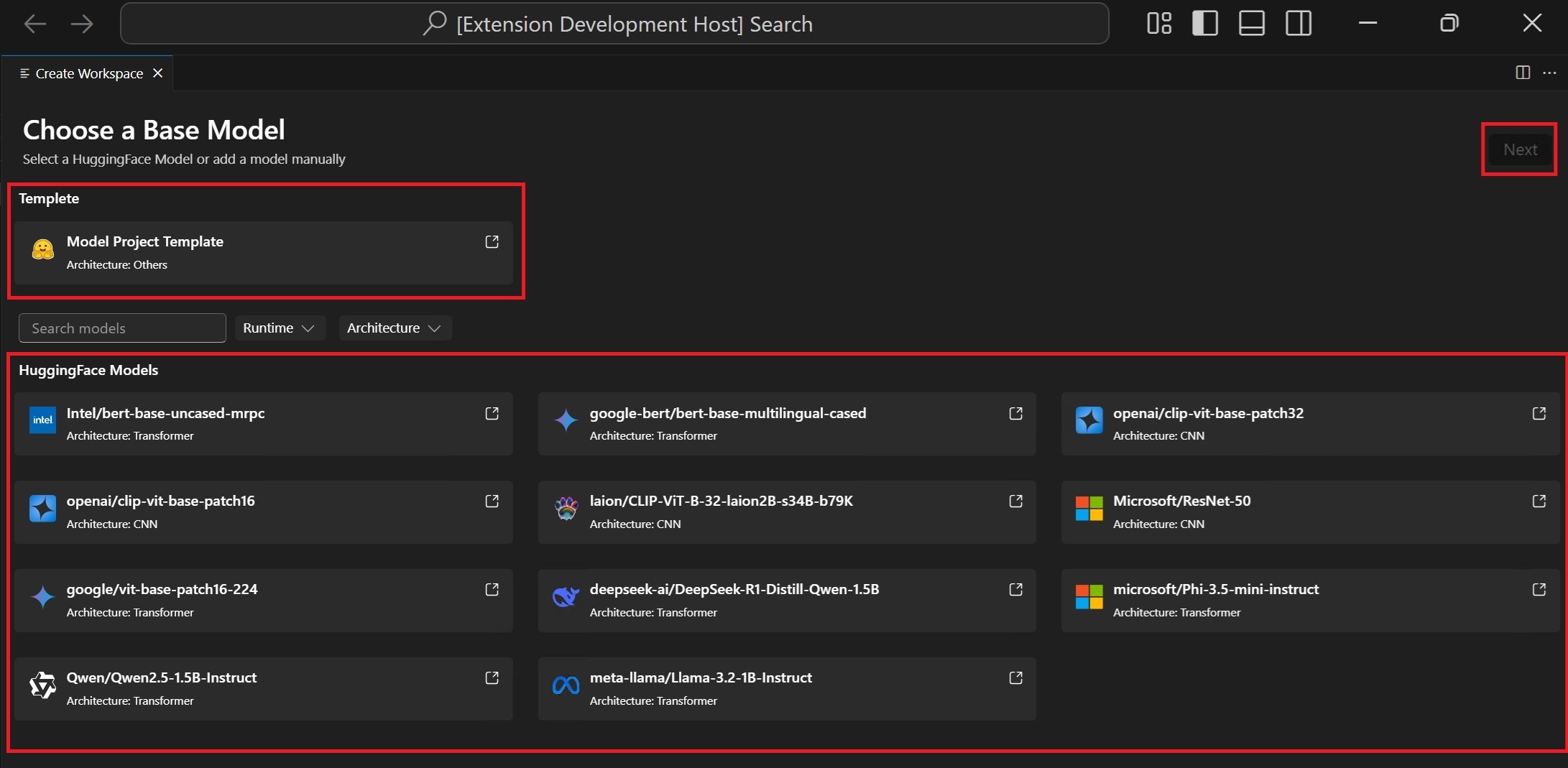
ベースモデルを選択する
Hugging Face Model: サポートされているモデルリストから、事前定義されたレシピを持つベースモデルを選択します。Model Template: モデルがベースモデルに含まれていない場合は、カスタマイズされたレシピ用に空のテンプレートを選択します (高度なシナリオ)。
-
プロジェクトの詳細を入力します。一意のプロジェクトフォルダーとプロジェクト名です。
指定したプロジェクト名の新しいフォルダーが、プロジェクトファイルを保存するために選択した場所に作成されます。
初めてモデルプロジェクトを作成する場合、環境のセットアップに時間がかかる場合があります。セットアップが完了しなくても問題ありません。準備ができたら、環境を再セットアップすることを選択できます。
各プロジェクトにはREADME.mdファイルが含まれています。閉じた場合は、ワークスペースから再度開くことができます。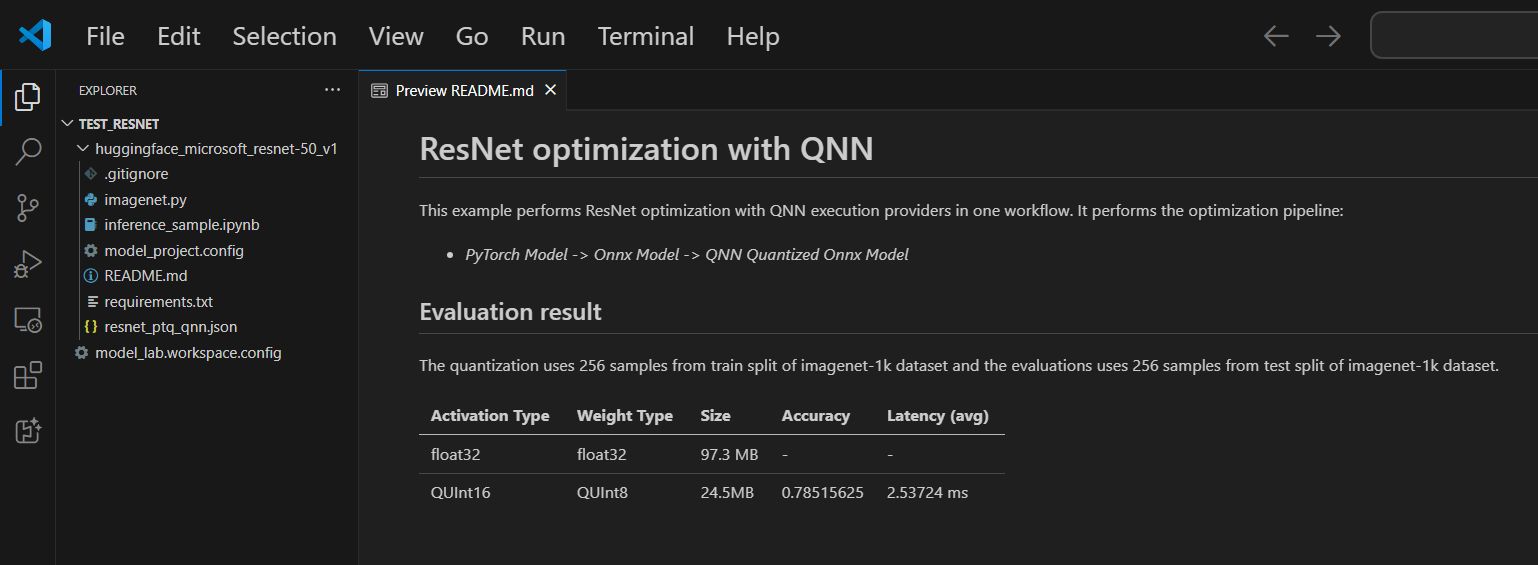
サポートされているモデル
Model Conversion は現在、PyTorch 形式の主要な Hugging Face モデルを含む、増え続けるモデルリストをサポートしています。詳細なモデルリストについては、モデルリストを参照してください。
(オプション) 既存のプロジェクトにモデルを追加する
-
モデルプロジェクトを開きます
-
Models > Conversion を選択し、右側のパネルで Add Models を選択します。
-
ベースモデルまたはテンプレートを選択し、Add を選択します。
新しいモデルファイルを含むフォルダーが、現在のプロジェクトフォルダー内に作成されます。
(オプション) 新しいモデルプロジェクトを作成する
-
モデルプロジェクトを開きます
-
Models > Conversion を選択し、右側のパネルで New Project を選択します。
-
または、現在のモデルプロジェクトを閉じて、最初から新しいプロジェクトを作成することもできます。
(オプション) モデルプロジェクトを削除する
-
モデルプロジェクトを開き、Models > Conversion を選択します。
-
右上隅のビューで、省略記号 (...) を選択し、Delete を選択して現在選択されているモデルプロジェクトを削除します。
ワークフローを実行する
モデル変換でワークフローを実行することは、事前に構築された ML モデルを最適化され量子化された ONNX モデルに変換する中心的なステップです。
-
VS Code で File > Open Folder を選択してモデルプロジェクトフォルダーを開きます。
-
ワークフロー構成を確認する
- Models > Conversion を選択します。
- ワークフローテンプレートを選択して変換レシピを表示します。

変換
ワークフローは常に変換ステップを実行し、モデルを ONNX 形式に変換します。このステップは無効にできません。
量子化
このセクションでは、量子化のパラメーターを構成できます。
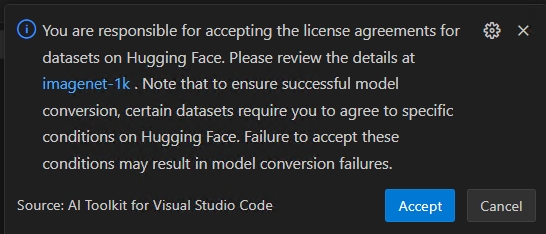
重要Hugging Face コンプライアンス警告: 量子化中には、キャリブレーションデータセットが必要です。続行する前にライセンス条項に同意するよう求められる場合があります。通知を見逃した場合、実行中のプロセスは一時停止し、入力が待機されます。通知が有効になっていて、必要なライセンスに同意していることを確認してください。
-
Activation Type: これは、ニューラルネットワークの各レイヤーの中間出力 (アクティベーション) を表すために使用されるデータ型です。
-
Weight Type: これは、モデルの学習されたパラメーター (重み) を表すために使用されるデータ型です。
-
Quantization Dataset: 量子化に使用されるキャリブレーションデータセット。
ワークフローが Hugging Face でライセンス契約の承認を必要とするデータセット (例: ImageNet-1k) を使用する場合、続行する前にデータセットページで条項に同意するよう求められます。これは法的コンプライアンスのために必要です。
-
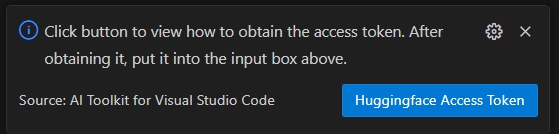
HuggingFace Access Token ボタンを選択して Hugging Face アクセストークンを取得します。
-
Open を選択して Hugging Face ウェブサイトを開きます。
-
Hugging Face ポータルでトークンを取得し、クイックピックに貼り付けます。Enter を押します。

-
-
Quantization Dataset Split: データセットには、検証、トレーニング、テストなどの異なる分割がある場合があります。
-
Quantization Dataset Size: モデルを量子化するために使用されるデータの数。
アクティベーションと重みタイプに関する詳細については、データ型の選択を参照してください。
このセクションを無効にすることもできます。この場合、ワークフローはモデルを ONNX 形式に変換するだけで、モデルを量子化しません。
評価
このセクションでは、モデルが変換されたプラットフォームに関係なく、評価に使用する実行プロバイダー (EP) を選択する必要があります。
- 評価対象: モデルを評価するターゲットデバイス。可能な値は次のとおりです。
- Qualcomm NPU: これを使用するには、互換性のある Qualcomm デバイスが必要です。
- AMD NPU: これを使用するには、サポートされている AMD NPU を搭載したデバイスが必要です。
- Intel CPU/GPU/NPU: これを使用するには、サポートされている Intel CPU/GPU/NPU を搭載したデバイスが必要です。
- NVIDIA TRT for RTX: これを使用するには、TensorRT for RTX をサポートする Nvidia GPU を搭載したデバイスが必要です。
- DirectML: これを使用するには、DirectML をサポートする GPU を搭載したデバイスが必要です。
- CPU: どの CPU でも動作します。
- Evaluation Dataset: 評価に使用されるデータセット。
- Evaluation Dataset Split: データセットには、検証、トレーニング、テストなどの異なる分割がある場合があります。
- Evaluation Dataset Size: モデルを評価するために使用されるデータの数。
このセクションを無効にすることもできます。この場合、ワークフローはモデルを ONNX 形式に変換するだけで、モデルを評価しません。
-
Run を選択してワークフローを実行します。
追跡しやすいように、ワークフロー名とタイムスタンプを使用してデフォルトのジョブ名 (例:
bert_qdq_2025-05-06_20-45-00) が生成されます。ジョブの実行中に、履歴ボードのステータスインジケーターまたはActionの下にある三点メニューを選択し、Stop Running を選択してジョブをキャンセルできます。
Hugging Face コンプライアンス警告: 量子化中には、キャリブレーションデータセットが必要です。続行する前にライセンス条項に同意するよう求められる場合があります。通知を見逃した場合、実行中のプロセスは一時停止し、入力が待機されます。通知が有効になっていて、必要なライセンスに同意していることを確認してください。
-
(オプション) クラウドでモデル変換を実行する
Cloud Conversion を使用すると、ローカルマシンに十分な計算能力やストレージ容量がない場合に、クラウドでモデル変換と量子化を実行できます。Cloud Conversion を使用するには、Azure サブスクリプションが必要です。
-
右上隅のドロップダウンから Run with Cloud を選択します。クラウド環境には推論用のターゲットプロセッサがないため、Evaluation セクションは無効になっています。
-
AI Toolkit はまず、Cloud Conversion 用の Azure リソースが準備されているかどうかを確認します。必要に応じて、Azure リソースをプロビジョニングするための Azure サブスクリプションとリソースグループを求められます。

-
プロビジョニングが完了すると、プロビジョニング構成はワークスペースのルートフォルダーにある
model_lab.workspace.provision.configに保存されます。この情報は、Azure リソースを再利用し、クラウド変換プロセスを高速化するためにキャッシュされます。新しいリソースを使用する場合は、このファイルを削除して Cloud Conversion を再度実行してください。 -
Azure Container App (ACA) ジョブがトリガーされ、Cloud Conversion が実行されます。実行中のジョブでは、次のことができます。
- ステータスリンクを選択して、Azure ACA ジョブ実行履歴ページに移動します。
- logs を選択して Azure Log Analytics に移動します。
- 更新ボタンを選択して、現在のジョブステータスを取得します。

-
LLM モデル変換に利用可能な GPU がない場合は、Run with Cloud を使用できます。Run with Cloud オプションは、モデル変換と量子化のみをサポートしています。変換されたモデルは、評価のためにローカルマシンにダウンロードする必要があります。
Run with Cloud は、DirectML または NVIDIA TRT for RTX ワークフローを使用したモデル変換をサポートしていません。
Recommended 列には、デバイスが変換されたモデルを実行する準備ができているかどうかに基づいて、推奨されるワークフローが表示されます。もちろん、ご希望のワークフローを選択することもできます。モデル変換と量子化: LLM モデルを除き、任意のデバイスでワークフローを実行できます。Quantization 構成は NPU 専用に最適化されています。ターゲットシステムが NPU でない場合は、このステップをオフにすることをお勧めします。
LLM モデル量子化: LLM モデルを量子化したい場合は、Nvidia GPU が必要です。
別のデバイスの GPU でモデルを量子化したい場合は、ご自身で環境をセットアップできます。ManualConversionOnGPU を参照してください。GPU が必要なのは「Quantization」ステップのみであることに注意してください。量子化後、NPU または CPU でモデルを評価できます。
再評価のヒント
モデルが正常に変換された後、再評価機能を使用して、モデル変換なしで再度評価を実行できます。
履歴ボードに移動し、モデル実行ジョブを見つけます。Action の下にある三点メニューを選択して、モデルを再評価します。
再評価のために異なる EP またはデータセットを選択できます。

失敗したジョブのヒント
ジョブがキャンセルされたり失敗したりした場合、ジョブ名を選択してワークフローを調整し、再度ジョブを実行できます。偶発的な上書きを避けるため、各実行では独自の構成と結果を含む新しい履歴フォルダーが作成されます。
一部のワークフローでは、最初に Hugging Face にログインする必要があります。ジョブがhuggingface_hub.errors.LocalTokenNotFoundError: Token is required ('token=True'), but no token found. You need to provide a token or be logged in to Hugging Face with 'hf auth login' or 'huggingface_hub.login'のような出力で失敗した場合は、https://huggingface.co/settings/tokens に移動し、指示に従ってログインプロセスを完了してから再試行してください。
再評価がMicrosoft Visual C++ Redistributable is not installedのような出力警告で失敗した場合は、以下のパッケージを手動でインストールする必要があります。
- Microsoft Visual C++ 再頒布可能パッケージ
- (ARM64 の場合、オプション) Microsoft C++ Build Tools からダウンロードします。インストール中に
C++ によるデスクトップ開発ワークロードも確認してください。
結果を表示する
Conversion の履歴ボードは、すべてのワークフロー実行を追跡、レビュー、管理するための中央ダッシュボードです。モデル変換と評価を実行するたびに、履歴ボードに新しいエントリが作成され、完全なトレーサビリティと再現性が確保されます。
-
レビューしたいワークフロー実行を見つけます。各実行はステータスインジケーター (例: Succeeded, Cancelled) とともにリストされます。
-
実行名を選択して変換構成を表示します。
-
ステータスインジケーターの下にある logs を選択して、ログと詳細な実行結果を表示します。
-
モデルが正常に変換されると、Metrics の下に評価結果が表示されます。精度、レイテンシ、スループットなどのメトリックが各実行とともに表示されます。

-
Action の下にある三点メニューを選択して、変換されたモデルを操作できます。

変換済みモデルパスをコピーする
- ドロップダウンから Copy model path を選択します。出力変換済みモデルパス (例:
c:/{workspace}/{model_project}/history/{workflow}/model/model.onnx) がクリップボードにコピーされ、参照できます。LLM モデルの場合、出力フォルダーが代わりにコピーされます。
モデル推論にサンプルノートブックを使用する
- ドロップダウンから Inference in Sample を選択します。
- Python 環境を選択する
- Python 仮想環境を選択するように求められます。デフォルトのランタイムは
C:\Users\{user_name}\.aitk\bin\model_lab_runtime\Python-WCR-win32-x64-3.12.9です。 - デフォルトのランタイムには必要なものがすべて含まれていることに注意してください。そうでない場合は、requirements.txt を手動でインストールしてください。
- Python 仮想環境を選択するように求められます。デフォルトのランタイムは
- サンプルは Jupyter Notebook で起動します。入力データやパラメーターをカスタマイズして、さまざまなシナリオをテストできます。
Cloud Conversion を使用するモデルの場合、ステータスがSucceededに変わった後、クラウドダウンロードアイコンを選択して、出力モデルをローカルマシンにダウンロードします。
構成ファイルや履歴関連ファイルなど、既存のローカルファイルを上書きしないように、不足しているファイルのみがダウンロードされます。クリーンなコピーをダウンロードしたい場合は、まずローカルフォルダーを削除してから再度ダウンロードしてください。
モデルの互換性: 変換されたモデルが推論サンプルで指定された EP をサポートしていることを確認してください。
サンプル場所: 推論サンプルは、履歴フォルダー内の実行成果物とともに保存されます。
エクスポートして共有する
履歴ボードに移動します。Export を選択して、モデルプロジェクトを他のユーザーと共有します。これにより、履歴フォルダーなしでモデルプロジェクトがコピーされます。モデルを他のユーザーと共有したい場合は、対応するジョブを選択します。これにより、モデルとその構成を含む選択された履歴フォルダーがコピーされます。
学んだこと
この記事では、次のことを学びました
- AI Toolkit for VS Code でモデル変換プロジェクトを作成します。
- 量子化および評価設定を含む変換ワークフローを構成します。
- 変換ワークフローを実行して、事前に構築されたモデルを最適化された ONNX モデルに変換します。
- メトリックやログを含む変換結果を表示します。
- モデル推論とテストにサンプルノートブックを使用します。
- モデルプロジェクトをエクスポートして他のユーザーと共有します。
- 異なる実行プロバイダーまたはデータセットを使用してモデルを再評価します。
- 失敗したジョブを処理し、再実行のために構成を調整します。
- サポートされているモデルと、変換および量子化の要件を理解します。