VS Code でのデータサイエンス チュートリアル
このチュートリアルでは、Visual Studio Code と Microsoft Python 拡張機能と一般的なデータサイエンスライブラリを使用して、基本的なデータサイエンスシナリオを探索する方法を説明します。具体的には、タイタニック号の乗客データを使用して、データサイエンス環境のセットアップ、データのインポートとクリーンアップ、タイタニック号での生存を予測するための機械学習モデルの作成、および生成されたモデルの精度の評価方法を学びます。
前提条件
このチュートリアルを完了するには、以下のインストールが必要です。まだインストールしていない場合は、必ずインストールしてください。
-
Visual Studio Marketplace から VS Code 用 Python 拡張機能と VS Code 用 Jupyter 拡張機能をインストールします。拡張機能のインストールに関する詳細については、拡張機能マーケットプレイスを参照してください。どちらの拡張機能も Microsoft が公開しています。
-
注: フルバージョンの Anaconda ディストリビューションが既にインストールされている場合は、Miniconda をインストールする必要はありません。または、Anaconda や Miniconda を使用したくない場合は、Python 仮想環境を作成し、pip を使用してチュートリアルに必要なパッケージをインストールできます。この方法を選択する場合、pandas、jupyter、seaborn、scikit-learn、keras、tensorflow の各パッケージをインストールする必要があります。
データサイエンス環境のセットアップ
Visual Studio Code と Python 拡張機能は、データサイエンスのシナリオに優れたエディターを提供します。Jupyter ノートブックのネイティブサポートと Anaconda を組み合わせることで、簡単に始めることができます。このセクションでは、チュートリアル用のワークスペースを作成し、チュートリアルに必要なデータサイエンスモジュールを含む Anaconda 環境を作成し、機械学習モデルの作成に使用する Jupyter ノートブックを作成します。
-
まず、データサイエンスチュートリアル用の Anaconda 環境を作成します。Anaconda コマンドプロンプトを開き、
conda create -n myenv python=3.10 pandas jupyter seaborn scikit-learn keras tensorflowを実行して、myenv という名前の環境を作成します。Anaconda 環境の作成と管理に関する追加情報については、Anaconda ドキュメントを参照してください。 -
次に、チュートリアル用の VS Code ワークスペースとして機能するフォルダーを便利な場所に作成し、
hello_dsという名前を付けます。 -
VS Code を起動し、ファイル > フォルダーを開く コマンドを使用して、プロジェクトフォルダーを VS Code で開きます。自分で作成したフォルダーなので、安全に開くことができます。
-
VS Code が起動したら、チュートリアルで使用する Jupyter ノートブックを作成します。コマンドパレット (⇧⌘P (Windows, Linux Ctrl+Shift+P)) を開き、作成: 新しい Jupyter Notebook を選択します。

注: または、VS Code のファイルエクスプローラーから、新しいファイルアイコンを使用して
hello.ipynbという名前の Notebook ファイルを作成することもできます。 -
ファイル > 名前を付けて保存... を使用して、ファイルを
hello.ipynbとして保存します。 -
ファイルが作成されると、開いている Jupyter ノートブックがノートブックエディターに表示されます。ネイティブの Jupyter ノートブックのサポートに関する詳細については、Jupyter Notebooks のトピックを参照してください。
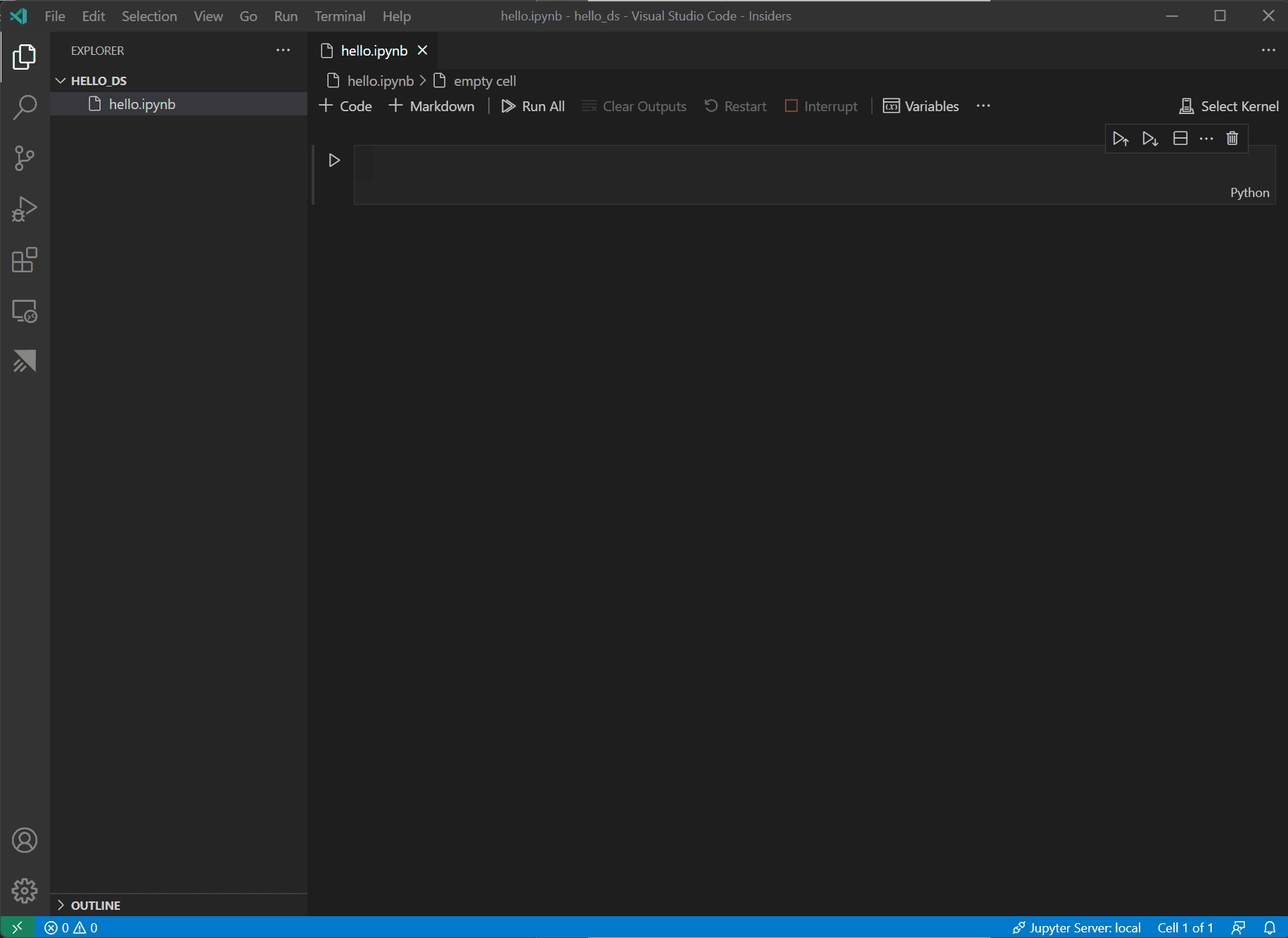
-
次に、ノートブックの右上にある カーネルを選択 を選択します。

-
上記で作成した Python 環境を選択して、カーネルを実行します。
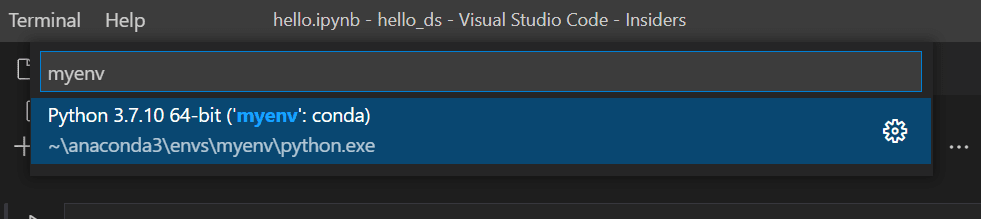
-
VS Code の統合ターミナルから環境を管理するには、(⌃` (Windows, Linux Ctrl+`)) で開きます。環境がアクティブ化されていない場合は、ターミナルでアクティブ化するのと同じようにアクティブ化できます (
conda activate myenv)。
データの準備
このチュートリアルでは、Vanderbilt 大学生物統計学部 https://hbiostat.org/data から取得され、OpenML.org で入手できる Titanic データセットを使用します。Titanic データは、タイタニック号の乗客の生存に関する情報と、年齢やチケットクラスなどの乗客の特性を提供します。このデータを使用して、チュートリアルでは、特定の乗客がタイタニック号の沈没で生き残ったかどうかを予測するモデルを確立します。このセクションでは、Jupyter ノートブックでデータをロードおよび操作する方法を示します。
-
まず、hbiostat.org から Titanic データを CSV ファイル (右上にあるダウンロードリンク) としてダウンロードし、
titanic3.csvという名前で、前のセクションで作成したhello_dsフォルダーに保存します。 -
まだ VS Code でファイルを開いていない場合は、ファイル > フォルダーを開く に移動して、
hello_dsフォルダーと Jupyter ノートブック (hello.ipynb) を開きます。 -
Jupyter ノートブック内で、まずデータを操作するために使用される2つの一般的なライブラリである pandas と numpy ライブラリをインポートし、Titanic データを pandas DataFrame にロードします。これを行うには、以下のコードをノートブックの最初のセルにコピーします。VS Code で Jupyter ノートブックを操作する方法の詳細については、Jupyter Notebooks の操作ドキュメントを参照してください。
import pandas as pd import numpy as np data = pd.read_csv('titanic3.csv') -
次に、セルの実行アイコンまたは Shift+Enter ショートカットを使用してセルを実行します。
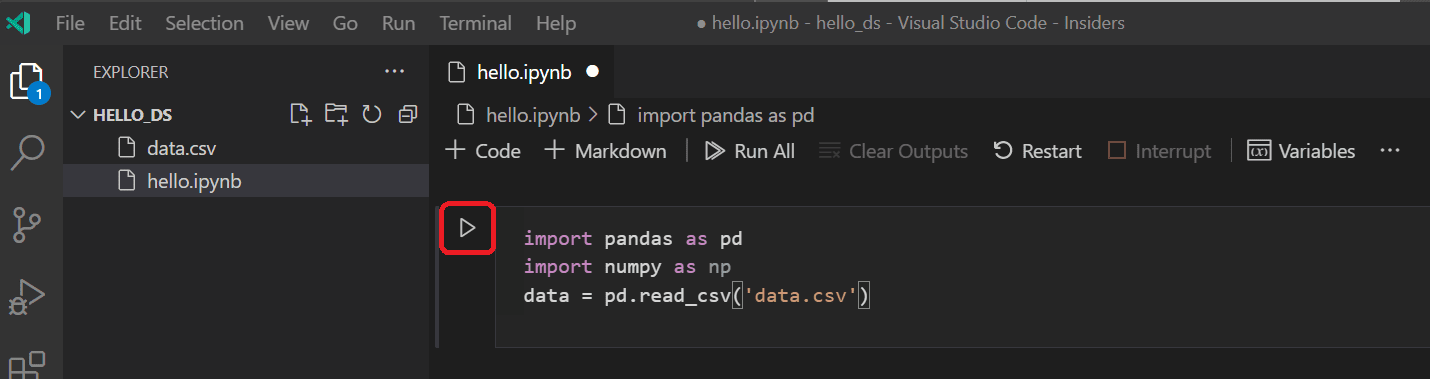
-
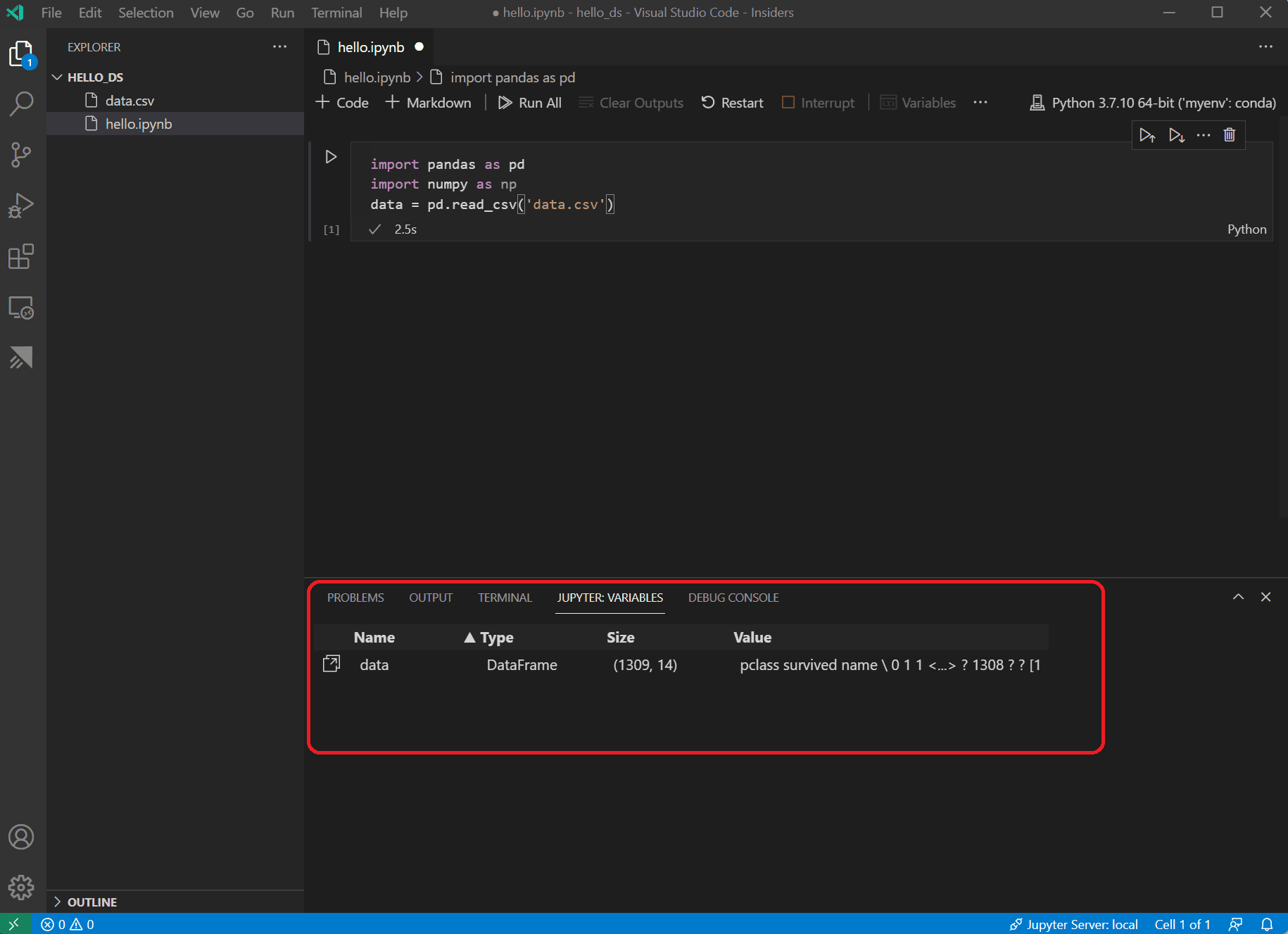
セルが実行を終了すると、変数エクスプローラーとデータビューアーを使用してロードされたデータを表示できます。まず、ノートブックの上部ツールバーにある 変数 アイコンを選択します。
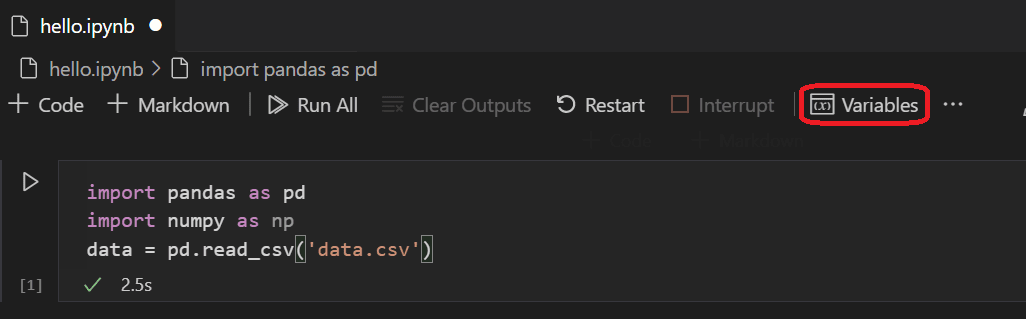
-
VS Code の下部に JUPYTER: 変数 ペインが開きます。これには、実行中のカーネルでこれまでに定義された変数のリストが含まれています。
-
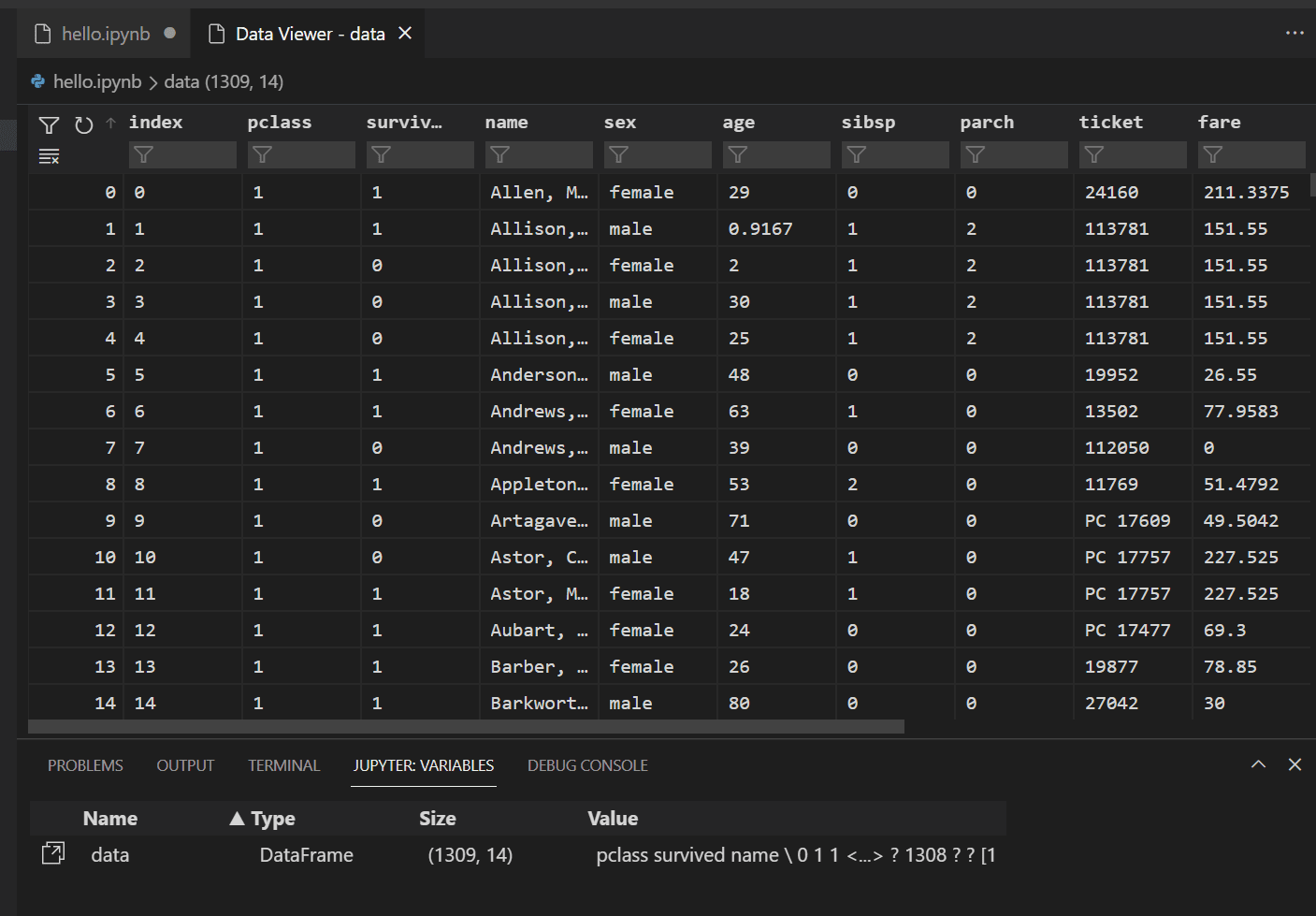
以前にロードした Pandas DataFrame のデータを表示するには、
data変数の左にあるデータビューアーアイコンを選択します。
-
データビューアーを使用して、データの行を表示、並べ替え、フィルター処理します。データをレビューした後、異なる変数間の関係を視覚化するために、データのいくつかの側面をグラフ化することが役立ちます。
または、Data Wrangler などの他の拡張機能が提供するデータ表示エクスペリエンスを使用することもできます。Data Wrangler 拡張機能は、データの洞察を表示し、データプロファイリング、品質チェック、変換などを実行するのに役立つ豊富なユーザーインターフェイスを提供します。ドキュメントで Data Wrangler 拡張機能の詳細をご覧ください。
-
データをグラフ化する前に、データに問題がないことを確認する必要があります。Titanic CSV ファイルを見ると、データが利用できないセルを識別するために疑問符 ("?") が使用されていることに気づくでしょう。
Pandas はこの値を DataFrame に読み込むことができますが、age などの列の結果は、そのデータ型が数値データ型ではなく object に設定され、グラフ化に問題があります。
この問題は、疑問符を Pandas が理解できる欠損値に置き換えることで修正できます。ノートブックの次のセルに以下のコードを追加して、age 列と fare 列の疑問符を numpy NaN 値に置き換えます。値を置き換えた後、列のデータ型も更新する必要があることに注意してください。
ヒント: 新しいセルを追加するには、既存のセルの左下隅にあるセル挿入アイコンを使用します。または、Esc を押してコマンドモードに入り、その後に B キーを押すこともできます。
data.replace('?', np.nan, inplace= True) data = data.astype({"age": np.float64, "fare": np.float64})注: 列に使用されたデータ型を確認する必要がある場合は、DataFrame dtypes 属性を使用できます。
-
データが整ったので、seaborn と matplotlib を使用して、データセットの特定の列が生存率にどのように関連しているかを確認できます。以下のコードをノートブックの次のセルに追加して実行し、生成されたプロットを表示します。
import seaborn as sns import matplotlib.pyplot as plt fig, axs = plt.subplots(ncols=5, figsize=(30,5)) sns.violinplot(x="survived", y="age", hue="sex", data=data, ax=axs[0]) sns.pointplot(x="sibsp", y="survived", hue="sex", data=data, ax=axs[1]) sns.pointplot(x="parch", y="survived", hue="sex", data=data, ax=axs[2]) sns.pointplot(x="pclass", y="survived", hue="sex", data=data, ax=axs[3]) sns.violinplot(x="survived", y="fare", hue="sex", data=data, ax=axs[4])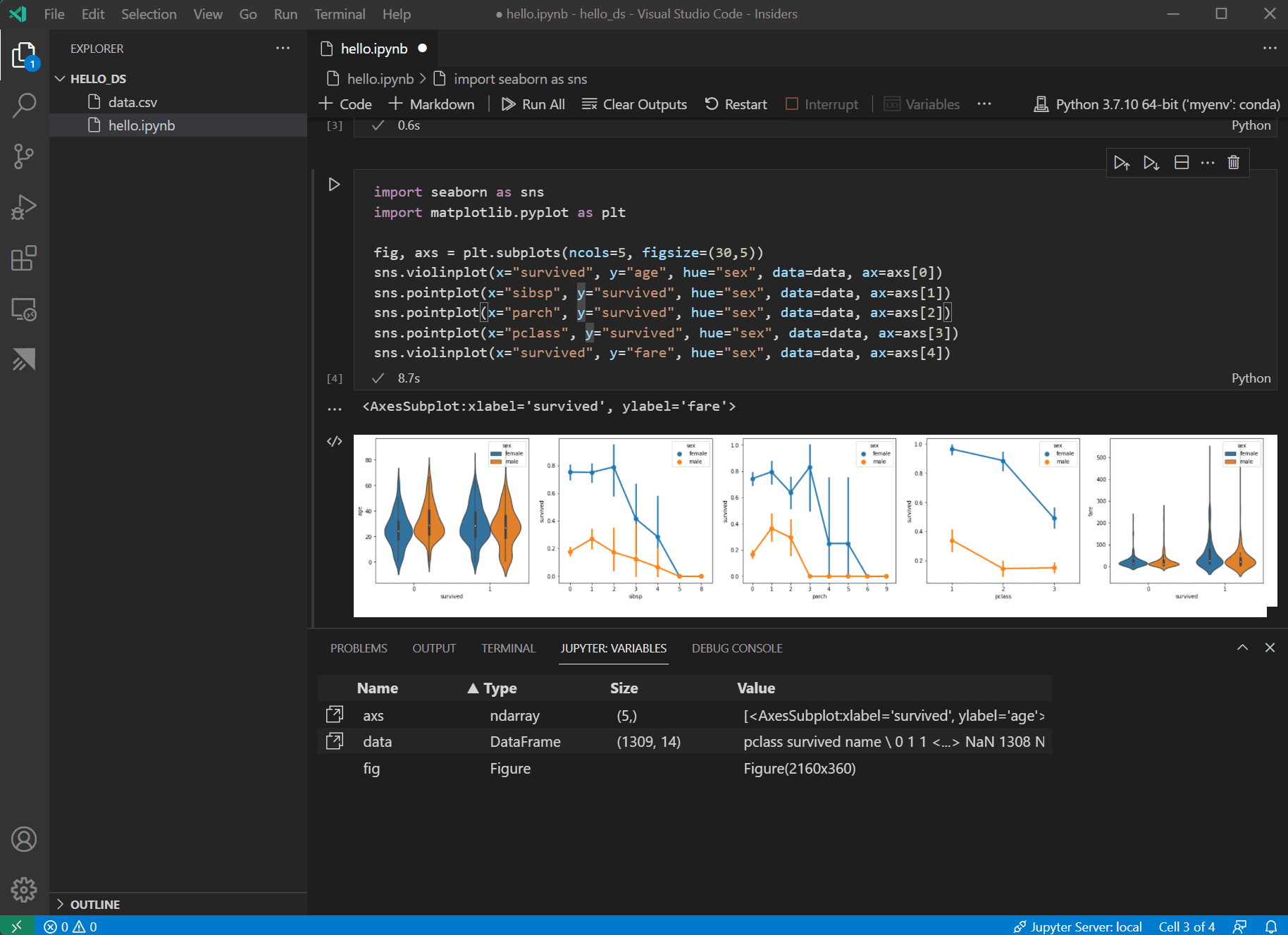
ヒント: グラフをすばやくコピーするには、グラフの右上隅にカーソルを合わせ、表示される クリップボードにコピー ボタンをクリックします。画像を拡大 ボタンをクリックすると、グラフの詳細をより詳しく表示することもできます。

-
これらのグラフは、生存とデータの入力変数との間のいくつかの関係を見るのに役立ちますが、pandas を使用して相関を計算することも可能です。そのためには、相関計算に使用されるすべての変数が数値である必要があり、現在、性別は文字列として保存されています。これらの文字列値を整数に変換するには、以下のコードを追加して実行します。
data.replace({'male': 1, 'female': 0}, inplace=True) -
次に、すべての入力変数間の相関を分析して、機械学習モデルへの最適な入力となる特徴量を特定できます。値が 1 に近いほど、値と結果の相関が高くなります。以下のコードを使用して、すべての変数と生存の間の関係を相関させます。
data.corr(numeric_only=True).abs()[["survived"]]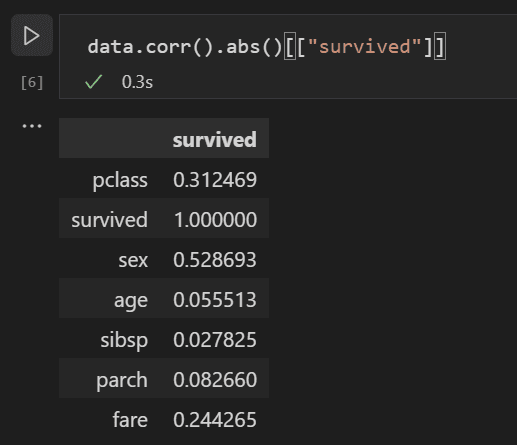
-
相関結果を見ると、性別のような一部の変数は生存とかなり高い相関がありますが、親族 (sibsp = 兄弟または配偶者、parch = 親または子供) のような変数はほとんど相関がないことがわかります。
sibsp と parch は生存率に影響を与える方法で関連していると仮定し、それらを「relatives」という新しい列にグループ化して、それらの組み合わせが生存率とより高い相関があるかどうかを確認してみましょう。これを行うには、特定の乗客について、sibsp と parch の数が 0 より大きいかどうかを確認し、そうであれば、彼らが乗船している親族がいたと言えます。
以下のコードを使用して、データセットに
relativesという新しい変数と列を作成し、相関を再度確認します。data['relatives'] = data.apply (lambda row: int((row['sibsp'] + row['parch']) > 0), axis=1) data.corr(numeric_only=True).abs()[["survived"]]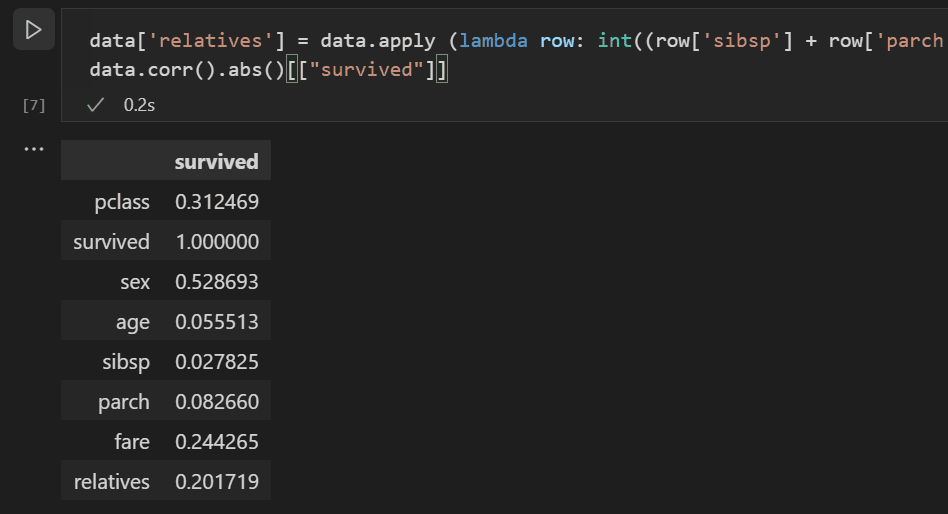
-
実際、親族がいたかどうかという観点から見ると、親族の数に関わらず、生存との相関が高いことがわかります。この情報に基づいて、モデルのトレーニングに使用できるデータセットを得るために、値の低い sibsp 列と parch 列、および NaN 値を持つ行をデータセットから削除できます。
data = data[['sex', 'pclass','age','relatives','fare','survived']].dropna()注: 年齢は直接的な相関が低いですが、他の入力と組み合わせて相関がある可能性があると考えるのが妥当であるため、残されました。
モデルのトレーニングと評価
データセットが準備できたので、モデルの作成を開始できます。このセクションでは、データセットの前処理、タイタニック号での生存率を決定する分類モデルのトレーニング、およびテストデータでそのモデルを使用してその精度を決定するために、scikit-learn ライブラリ (いくつかの便利なヘルパー関数を提供するため) を使用します。
-
モデルをトレーニングするための一般的な最初のステップは、データセットをトレーニングデータと検証データに分割することです。これにより、データの一部をモデルのトレーニングに使用し、データの一部をモデルのテストに使用できます。すべてのデータでモデルをトレーニングした場合、モデルがまだ見ていないデータに対して実際にどの程度うまく機能するかを推定する方法がありません。scikit-learn ライブラリの利点は、データセットをトレーニングデータとテストデータに分割するためのメソッドを具体的に提供することです。
データを分割するために、ノートブックに以下のコードを含むセルを追加して実行します。
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(data[['sex','pclass','age','relatives','fare']], data.survived, test_size=0.2, random_state=0) -
次に、すべての特徴量が等しく扱われるように入力を正規化します。たとえば、データセット内では年齢の値が約 0 ~ 100 の範囲であるのに対し、性別は 1 または 0 しかありません。すべての変数を正規化することで、値の範囲がすべて同じになるようにできます。新しいコードセルで以下のコードを使用して、入力値をスケーリングします。
from sklearn.preprocessing import StandardScaler sc = StandardScaler() X_train = sc.fit_transform(x_train) X_test = sc.transform(x_test) -
データをモデル化するために選択できる機械学習アルゴリズムはたくさんあります。scikit-learn ライブラリは、それらの多くをサポートし、シナリオに適したものを選択するのに役立つ チャートも提供しています。ここでは、分類問題で一般的なアルゴリズムである Naïve Bayes アルゴリズムを使用します。以下のコードを含むセルを追加して、アルゴリズムを作成およびトレーニングします。
from sklearn.naive_bayes import GaussianNB model = GaussianNB() model.fit(X_train, y_train) -
トレーニング済みモデルを使用すると、トレーニングから保留されていたテストデータセットに対して試すことができます。以下のコードを追加して実行し、テストデータの出力を予測し、モデルの精度を計算します。
from sklearn import metrics predict_test = model.predict(X_test) print(metrics.accuracy_score(y_test, predict_test))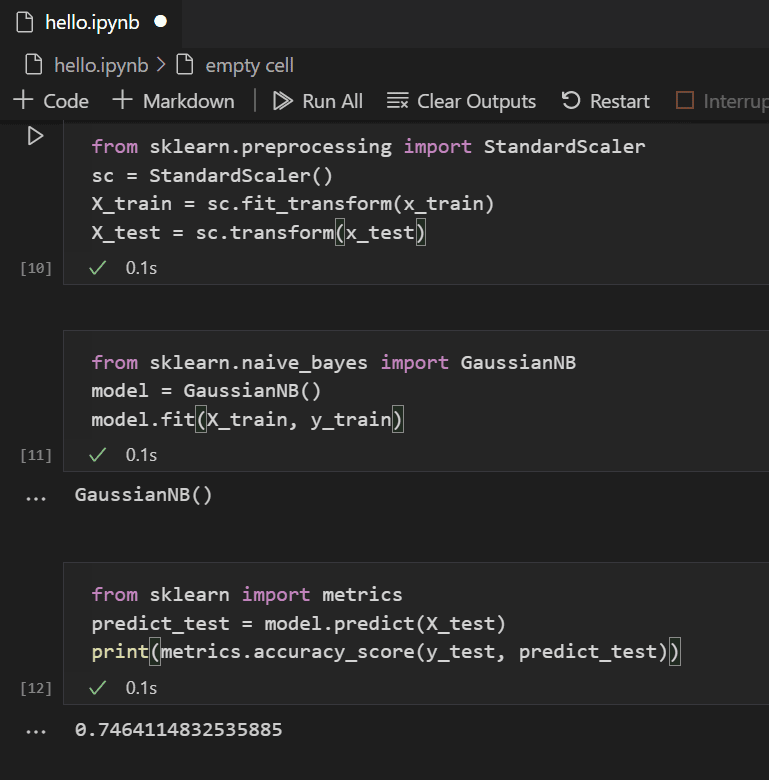
テストデータの結果を見ると、トレーニング済みアルゴリズムの生存推定成功率は約 75% であったことがわかります。
(オプション) ニューラルネットワークの使用
ニューラルネットワークは、人間のニューロンの側面をモデル化する重みと活性化関数を使用して、提供された入力に基づいて結果を決定するモデルです。以前に検討した機械学習アルゴリズムとは異なり、ニューラルネットワークは、問題セットに最適なアルゴリズムを事前に知る必要がないディープラーニングの一種です。さまざまなシナリオで使用でき、分類はその1つです。このセクションでは、Keras ライブラリと TensorFlow を使用してニューラルネットワークを構築し、タイタニックデータセットをどのように処理するかを探ります。
-
最初のステップは、必要なライブラリをインポートし、モデルを作成することです。この場合、Sequential ニューラルネットワークを使用します。これは、複数の層が順次互いに供給される層状のニューラルネットワークです。
from keras.models import Sequential from keras.layers import Dense model = Sequential() -
モデルを定義したら、次のステップはニューラルネットワークの層を追加することです。今のところ、物事をシンプルに保ち、3つの層だけを使用しましょう。ニューラルネットワークの層を作成するために以下のコードを追加します。
model.add(Dense(5, kernel_initializer = 'uniform', activation = 'relu', input_dim = 5)) model.add(Dense(5, kernel_initializer = 'uniform', activation = 'relu')) model.add(Dense(1, kernel_initializer = 'uniform', activation = 'sigmoid'))- 最初の層は、性別、pclass、年齢、親族、運賃という5つの入力があるため、次元は5に設定されます。
- 最後の層は1を出力する必要があります。これは、乗客が生き残るかどうかを示す1次元の出力が必要だからです。
- 中間層は、簡潔さのために5に保たれましたが、その値は異なっていてもよかったでしょう。
活性化関数として、最初の2つの層では優れた汎用活性化関数である整流線形単位 (relu) が使用され、最後の層では、必要な出力 (乗客が生き残るかどうか) を0~1の範囲 (乗客が生き残る確率) にスケーリングする必要があるため、シグモイド活性化関数が必要です。
このコード行で構築したモデルの概要も確認できます。
model.summary()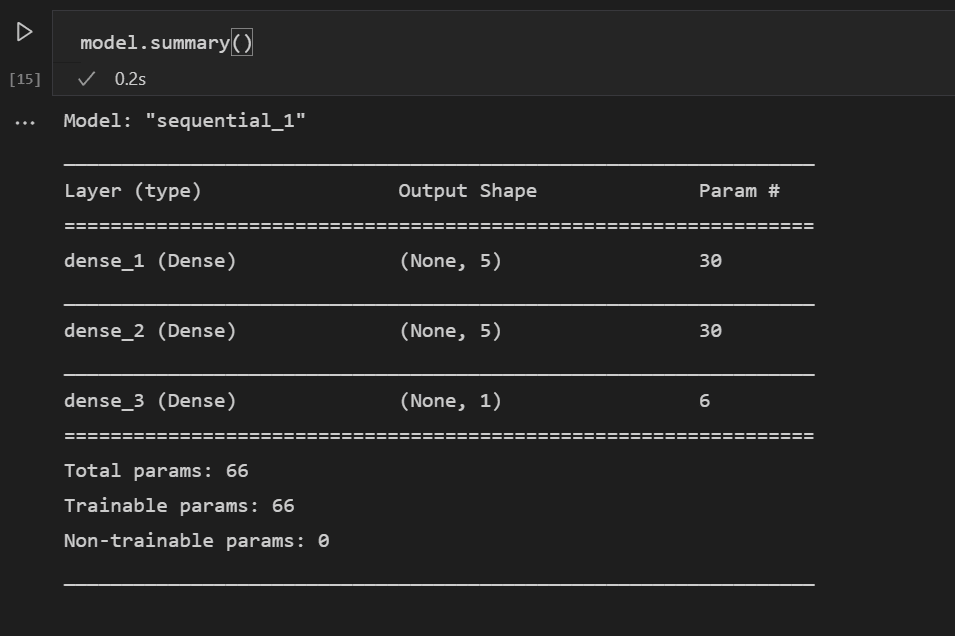
-
モデルが作成されたら、コンパイルする必要があります。これには、使用する最適化の種類、損失の計算方法、および最適化すべきメトリックを定義する必要があります。モデルを構築およびトレーニングするために以下のコードを追加します。トレーニング後、精度が約61%であることがわかります。
注: このステップは、マシンによって数秒から数分かかる場合があります。
model.compile(optimizer="adam", loss='binary_crossentropy', metrics=['accuracy']) model.fit(X_train, y_train, batch_size=32, epochs=50)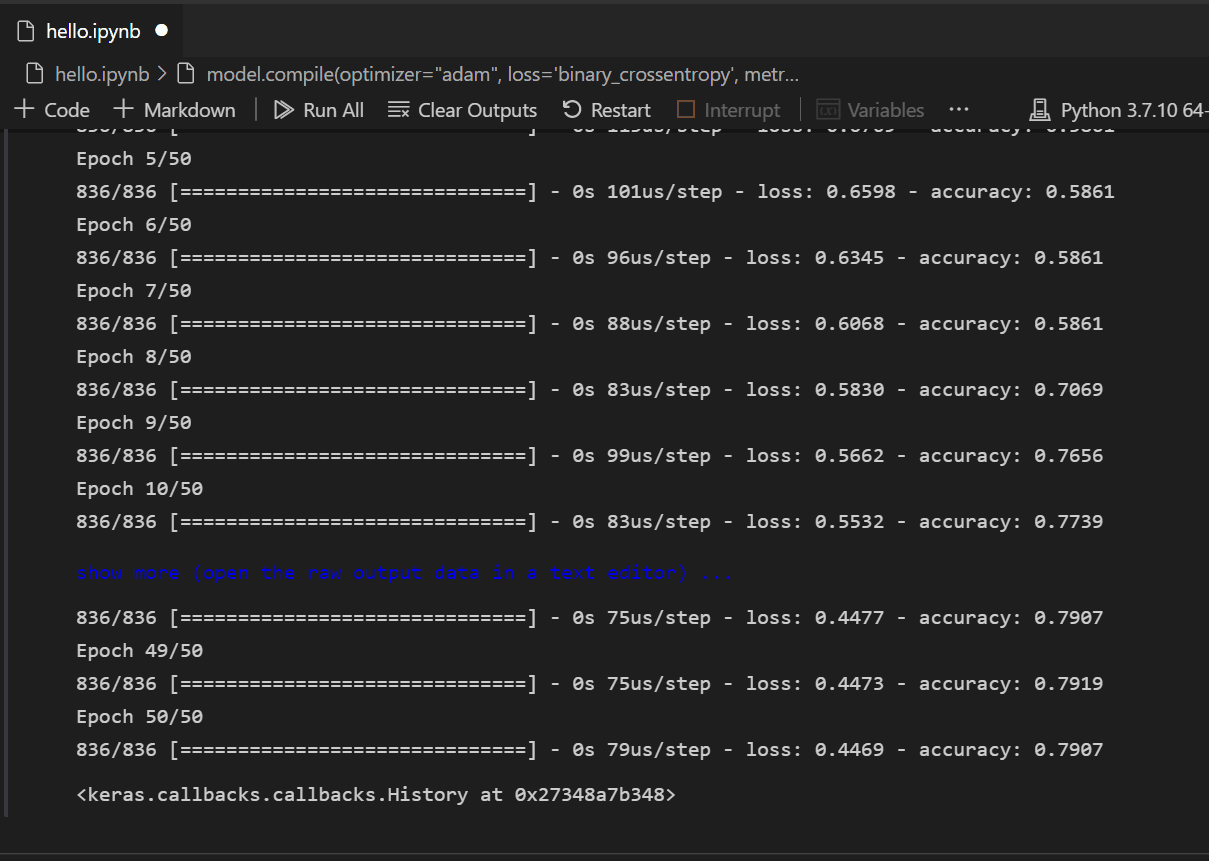
-
モデルが構築され、トレーニングされたので、テストデータに対してどのように機能するかを確認できます。
y_pred = np.rint(model.predict(X_test).flatten()) print(metrics.accuracy_score(y_test, y_pred))
トレーニングと同様に、乗客の生存予測において 79% の精度が得られることがわかります。このシンプルなニューラルネットワークを使用すると、以前に試したナイーブベイズ分類器の 75% の精度よりも良い結果が得られます。
次のステップ
Visual Studio Code で機械学習を実行する基本に慣れたところで、確認すべき他の Microsoft リソースとチュートリアルをいくつか紹介します。
- データサイエンス プロファイル テンプレート - 厳選された拡張機能、設定、スニペットのセットで新しい プロファイル を作成します。
- Visual Studio Code での Jupyter Notebooks の操作の詳細をご覧ください (ビデオ)。
- VS Code 用 Azure Machine Learning を使ってみることで、Azure の機能を使ってモデルをデプロイおよび最適化できます。
- Azure Open Data Sets でさらに探索するデータを見つけましょう。