VS Code で Data Wrangler を始める
Data Wrangler は、VS Code および VS Code Jupyter Notebooks に統合された、コード中心のデータ表示およびクリーニングツールです。データ表示・分析のための豊富なユーザーインターフェース、洞察に富んだ列統計と視覚化、そしてデータのクリーニングと変換時に Pandas コードを自動生成する機能を提供します。
以下は、ノートブックから Data Wrangler を開き、組み込み操作でデータを分析・クリーニングする例です。その後、自動生成されたコードはノートブックにエクスポートされます。

このドキュメントでは、以下の方法について説明します。
- Data Wrangler のインストールとセットアップ
- ノートブックから Data Wrangler を起動する
- データファイルから Data Wrangler を起動する
- Data Wrangler を使用してデータを探索する
- Data Wrangler を使用してデータに対する操作とクリーニングを実行する
- データラングリングコードを編集してノートブックにエクスポートする
- トラブルシューティングとフィードバックの提供
環境をセットアップする
- まだインストールしていない場合は、Python をインストールしてください。重要: Data Wrangler は Python バージョン 3.8 以降のみをサポートしています。
- Visual Studio Code をインストールします。
- Data Wrangler 拡張機能をインストールする
Data Wrangler を初めて起動すると、接続したい Python カーネルを尋ねられます。また、Pandas など、必要な Python パッケージがインストールされているかどうかもマシンと環境をチェックします。
以下は、Python と Python パッケージの必要なバージョンと、それらが Data Wrangler によって自動的にインストールされるかどうかのリストです。
| 名前 | 最低必要バージョン | 自動インストール |
|---|---|---|
| Python | 3.8 | いいえ |
| pandas | 0.25.2 | はい |
これらの依存関係が環境に見つからない場合、Data Wrangler は pip を使用してそれらをインストールしようとします。Data Wrangler が依存関係をインストールできない場合、最も簡単な回避策は pip install を手動で実行し、Data Wrangler を再度起動することです。これらの依存関係は、Data Wrangler が Python および Pandas コードを生成するために必要です。
Data Wrangler を開く
Data Wrangler を使用している間はいつでもサンドボックス環境にいることになり、安全にデータを探索し、変換することができます。元のデータセットは、変更を明示的にエクスポートするまで変更されません。
Jupyter Notebook から Data Wrangler を起動する
Jupyter Notebook から Data Wrangler を起動するには、3 つの方法があります。

- Jupyter > 変数パネルで、サポートされているデータオブジェクトの横に、Data Wrangler を起動するボタンが表示されます。
- ノートブックに Pandas データフレームがある場合、データフレームを出力するコードを実行した後、セルの下部にData Wrangler で 'df' を開くボタン (ここで 'df' はデータフレームの変数名) が表示されます。これには、1)
df.head()、2)df.tail()、3)display(df)、4)print(df)、5)dfが含まれます。 - ノートブックツールバーでデータの表示を選択すると、ノートブック内のサポートされているすべてのデータオブジェクトのリストが表示されます。次に、そのリストから Data Wrangler で開きたい変数を選択できます。
ファイルから直接 Data Wrangler を起動する
ローカルファイル (例: .csv) から Data Wrangler を直接起動することもできます。これを行うには、開きたいファイルを含む任意のフォルダーを VS Code で開きます。ファイルエクスプローラービューで、ファイルを右クリックし、Data Wrangler で開くをクリックします。
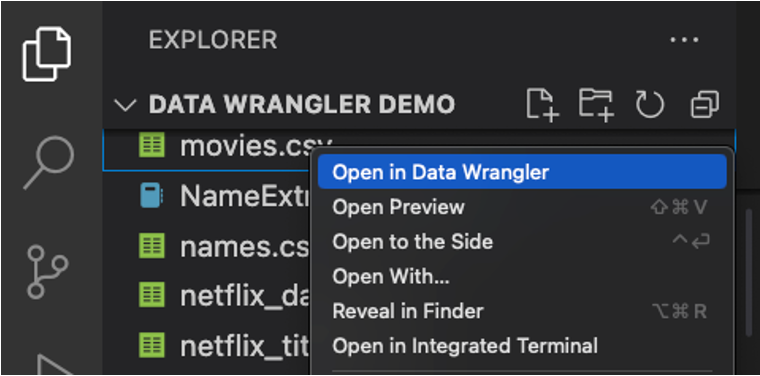
Data Wrangler は現在、以下のファイルタイプをサポートしています。
.csv/.tsv.xls/.xlsx.parquet
ファイルの種類に応じて、区切り文字やシートを指定できます。
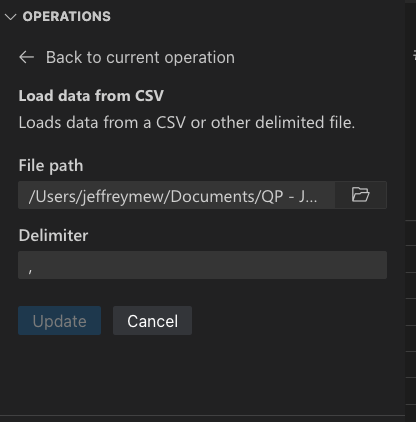
これらのファイルタイプを Data Wrangler でデフォルトで開くように設定することもできます。
UIツアー
Data Wrangler には、データ操作時に2つのモードがあります。各モードの詳細は以下のセクションで説明します。
- 表示モード: 表示モードは、データを素早く表示、フィルタリング、ソートするためにインターフェースを最適化します。このモードは、データセットの初期探索に最適です。
- 編集モード: 編集モードは、データセットに変換、クリーニング、または変更を適用するためにインターフェースを最適化します。インターフェースでこれらの変換を適用すると、Data Wrangler は関連する Pandas コードを自動的に生成し、これを再利用のためにノートブックにエクスポートできます。
注: デフォルトでは、Data Wrangler は表示モードで開きます。この動作は、設定エディター で変更できます。

表示モードインターフェース

-
データの概要パネルには、データセット全体の詳細な概要統計、または特定の列が選択されている場合はその列の統計が表示されます。
-
列ヘッダーメニューから、列にデータフィルター/ソートを適用できます。
-
Data Wrangler の表示モードと編集モードを切り替えて、組み込みのデータ操作にアクセスします。
-
クイックインサイトヘッダーでは、各列に関する貴重な情報を素早く確認できます。列のデータ型に応じて、クイックインサイトはデータの分布やデータポイントの頻度、欠損値と一意の値を示します。
-
データグリッドは、データセット全体を表示できるスクロール可能なペインを提供します。
編集モードインターフェース
編集モードに切り替えると、Data Wrangler で追加の機能とユーザーインターフェース要素が有効になります。次のスクリーンショットでは、Data Wrangler を使用して、最後の列の欠損値をその列の中央値に置き換えています。
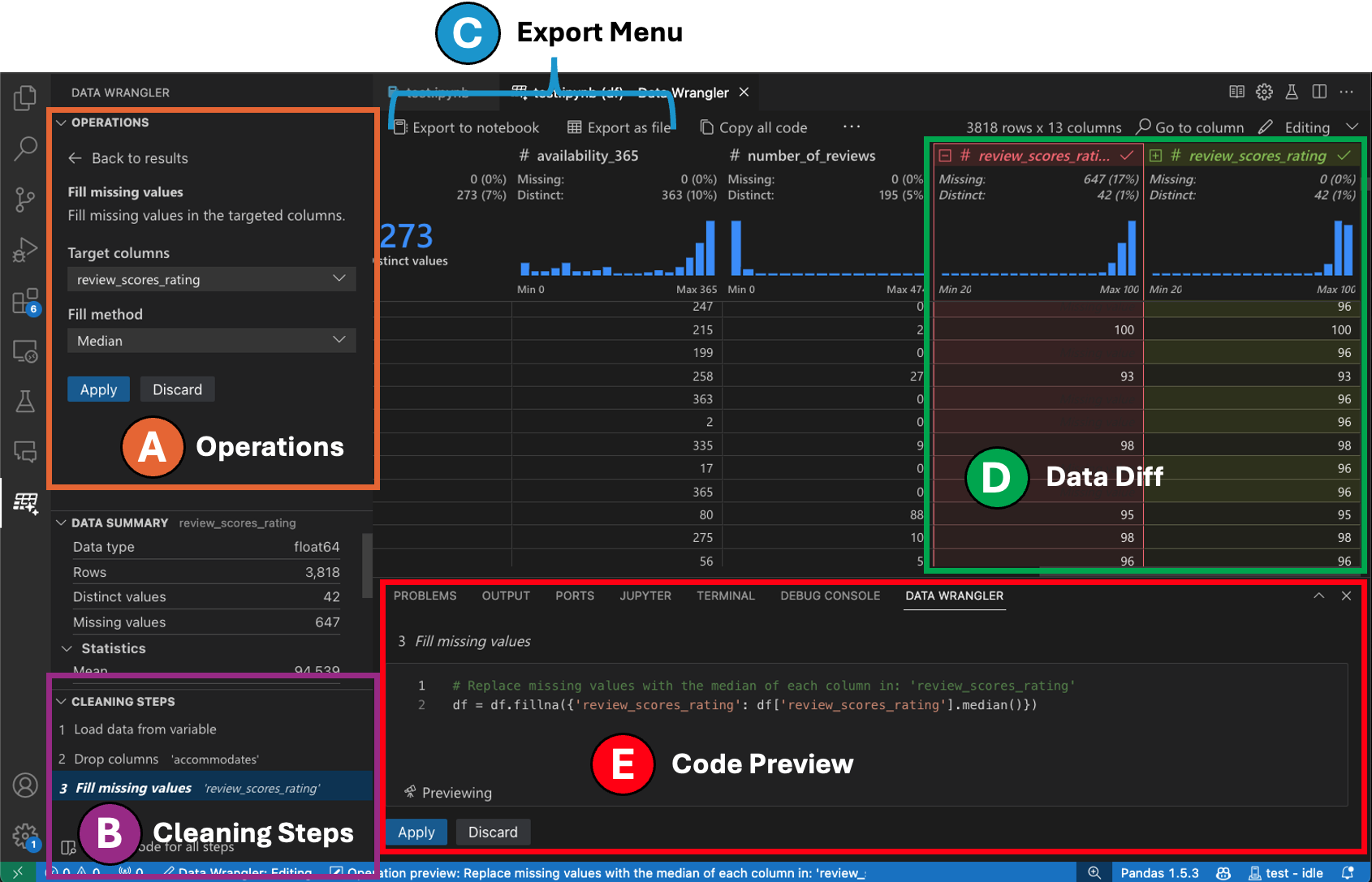
-
操作パネルでは、Data Wrangler の組み込みデータ操作をすべて検索できます。操作はカテゴリ別に整理されています。
-
クリーニング手順パネルには、以前に適用されたすべての操作のリストが表示されます。これにより、ユーザーは特定の操作を元に戻したり、最新の操作を編集したりできます。手順を選択すると、データ差分ビューで変更がハイライト表示され、その操作に関連付けられた生成されたコードが表示されます。
-
エクスポートメニューを使用すると、コードを Jupyter Notebook にエクスポートしたり、データを新しいファイルにエクスポートしたりできます。
-
操作を選択し、データへの影響をプレビューしている場合、グリッドにはデータに加えた変更のデータ差分ビューがオーバーレイされます。
-
コードプレビューセクションには、操作が選択されたときに Data Wrangler が生成した Python および Pandas コードが表示されます。操作が選択されていない場合は空のままです。生成されたコードを編集すると、データグリッドでデータへの影響がハイライト表示されます。
Data Wrangler の操作
組み込みの Data Wrangler の操作は、操作パネルから選択できます。
次の表は、Data Wrangler の初回リリースで現在サポートされている Data Wrangler の操作を示しています。近い将来、さらに多くの操作を追加する予定です。
| 操作 | 説明 |
|---|---|
| ソート | 列を昇順または降順でソートする |
| フィルター | 1つ以上の条件に基づいて行をフィルタリングする |
| テキスト長の計算 | テキスト列内の各文字列値の長さに等しい値を持つ新しい列を作成する |
| ワンホットエンコード | カテゴリデータを各カテゴリの新しい列に分割する |
| マルチラベルバイナライザ | 区切り文字を使用してカテゴリデータを各カテゴリの新しい列に分割する |
| 数式から列を作成 | カスタムの Python 数式を使用して列を作成する |
| 列の型の変更 | 列のデータ型を変更する |
| 列の削除 | 1つ以上の列を削除する |
| 列の選択 | 残りを削除して保持する1つ以上の列を選択する |
| 列の名前変更 | 1つ以上の列の名前を変更する |
| 列のクローン | 1つ以上の列のコピーを作成する |
| 欠損値の削除 | 欠損値を含む行を削除する |
| 重複行の削除 | 1つ以上の列に重複する値を持つすべての行を削除する |
| 欠損値の入力 | 欠損値のあるセルを新しい値に置き換える |
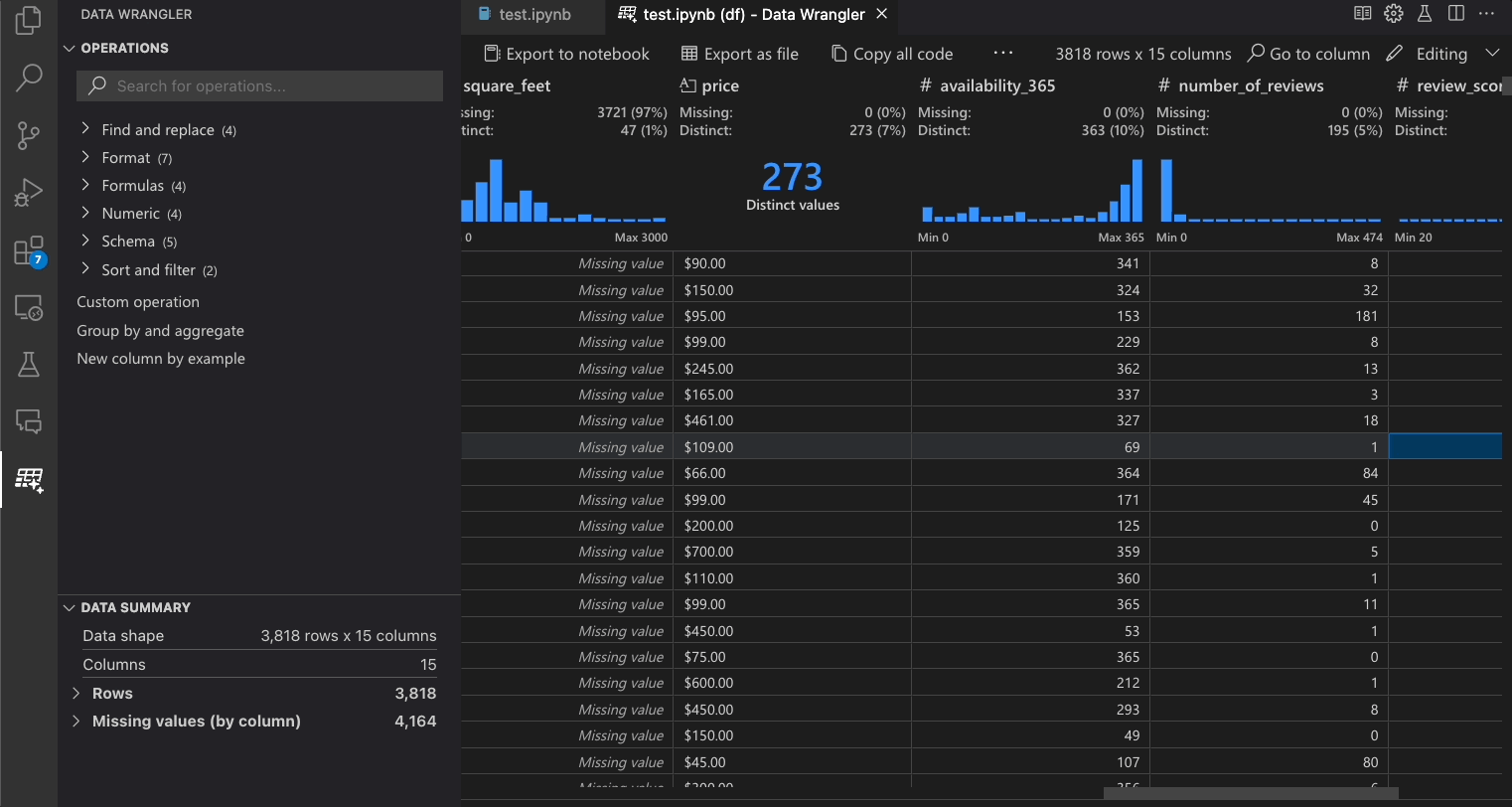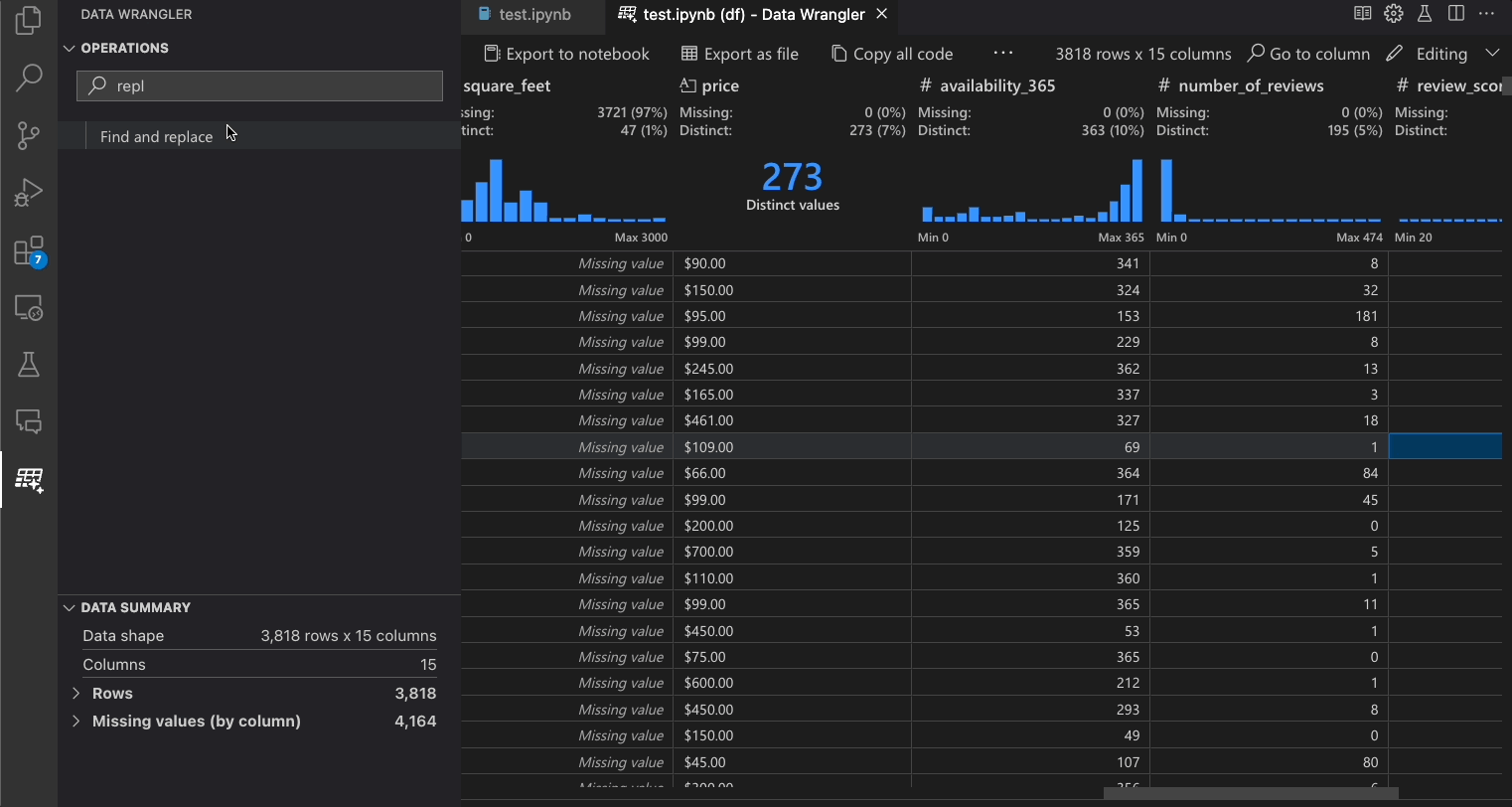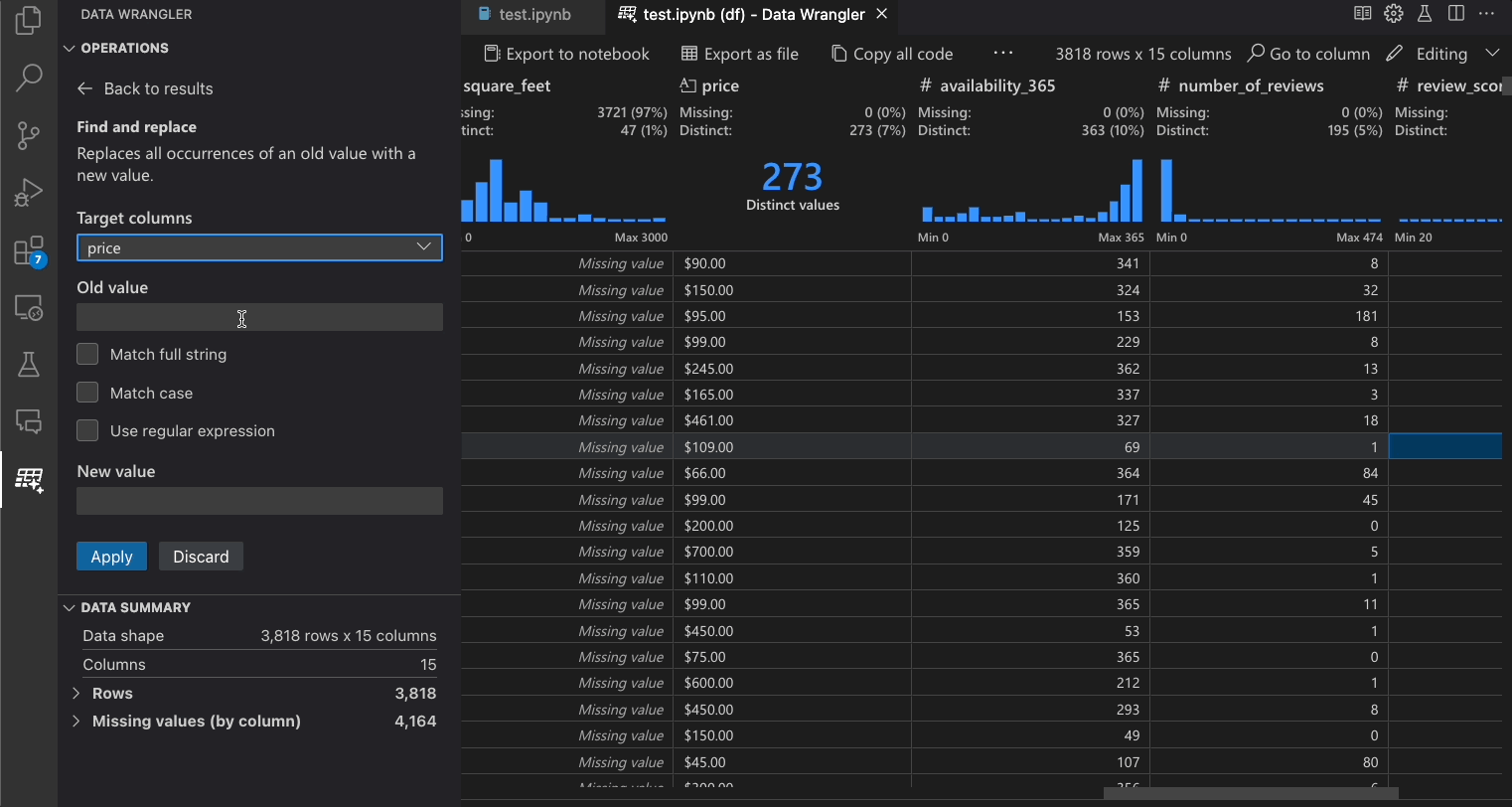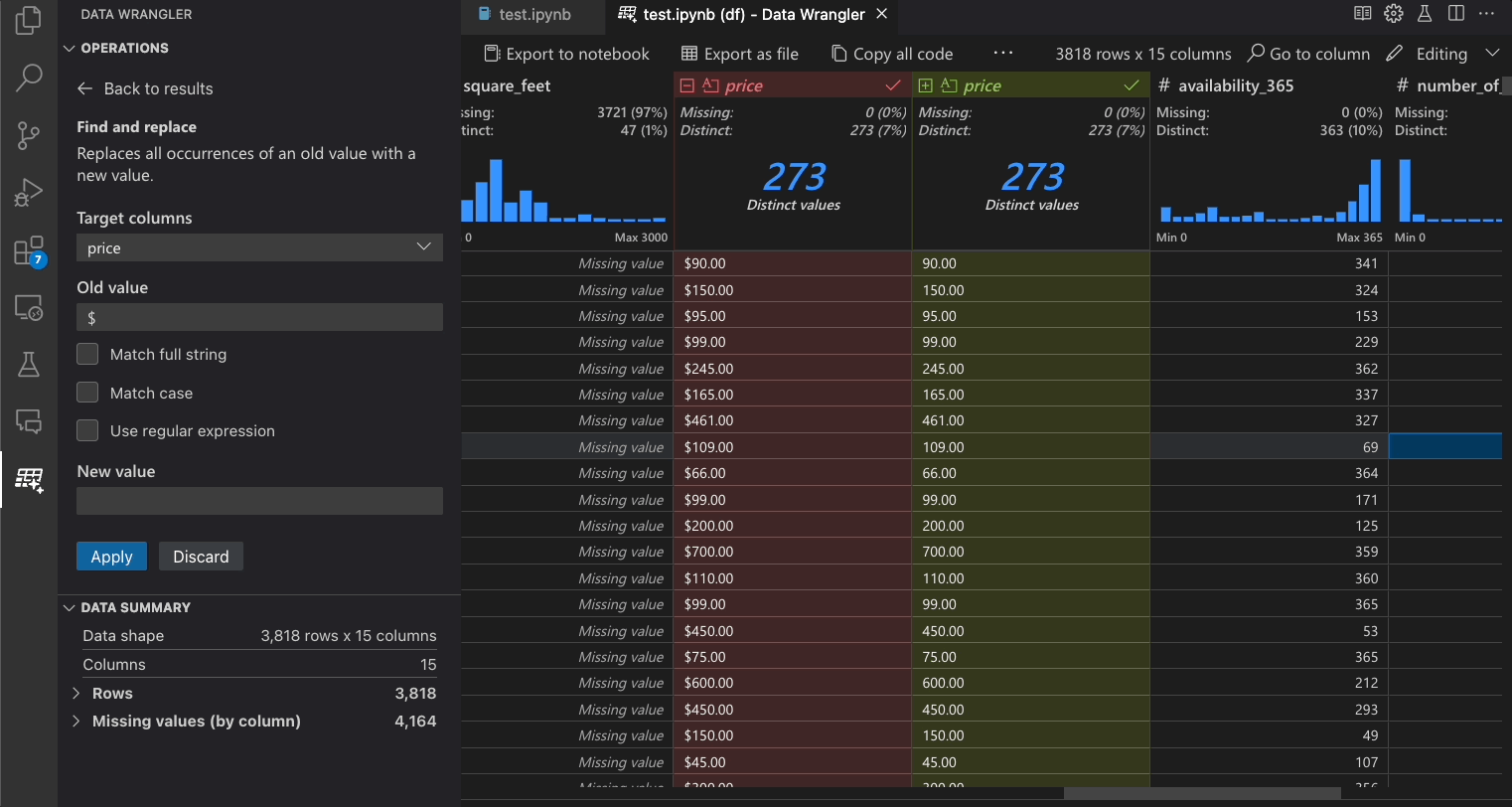
| 検索と置換 | 一致するパターンを持つセルを置き換える |
| 列によるグループ化と集計 | 列でグループ化して結果を集計する |
| 空白の削除 | テキストの先頭と末尾から空白を削除する |
| テキストの分割 | ユーザー定義の区切り文字に基づいて列を複数の列に分割する |
| 最初の文字を大文字にする | 最初の文字を大文字に、残りを小文字に変換する |
| テキストを小文字に変換 | テキストを小文字に変換 |
| テキストを大文字に変換 | テキストを大文字に変換 |
| 例による文字列変換 | 提供された例からパターンが検出されたときに、文字列変換を自動的に実行する |
| 例による DateTime フォーマット | 提供された例からパターンが検出されたときに、DateTime フォーマットを自動的に実行する |
| 例による新しい列 | 提供された例からパターンが検出されたときに、列を自動的に作成する |
| 最小/最大値のスケーリング | 数値列を最小値と最大値の間でスケーリングする |
| 丸め | 指定された小数点以下の桁数に数値を丸める |
| 切り捨て (floor) | 数値を最も近い整数に切り捨てる |
| 切り上げ (ceiling) | 数値を最も近い整数に切り上げる |
| カスタム操作 | 既存の列から導出された例に基づいて、新しい列を自動的に作成する |
Data Wrangler でサポートしてほしい操作が不足している場合は、Data Wrangler GitHub リポジトリで機能リクエストを提出してください。
前のステップの変更
生成されたコードの各ステップは、クリーニング手順パネルから変更できます。まず、変更したいステップを選択します。次に、操作に変更を加える (コードまたは操作パネルを介して) と、データへの変更の影響がグリッドビューでハイライト表示されます。

コードの編集とエクスポート
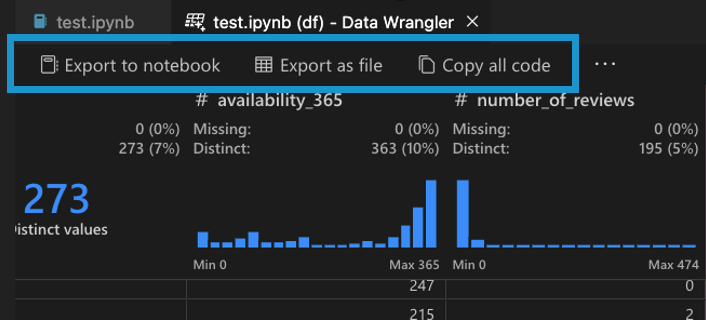
Data Wrangler でデータクリーニングのステップが完了したら、Data Wrangler からクリーニング済みデータセットをエクスポートする方法は3つあります。
- ノートブックにコードをエクスポートして終了: これにより、生成されたすべてのデータクリーニングコードが Python 関数としてパッケージ化され、Jupyter Notebook に新しいセルが作成されます。
- データをファイルにエクスポート: これにより、クリーニングされたデータセットが新しい CSV または Parquet ファイルとしてマシンに保存されます。
- コードをクリップボードにコピー: これにより、Data Wrangler がデータクリーニング操作のために生成したすべてのコードがコピーされます。
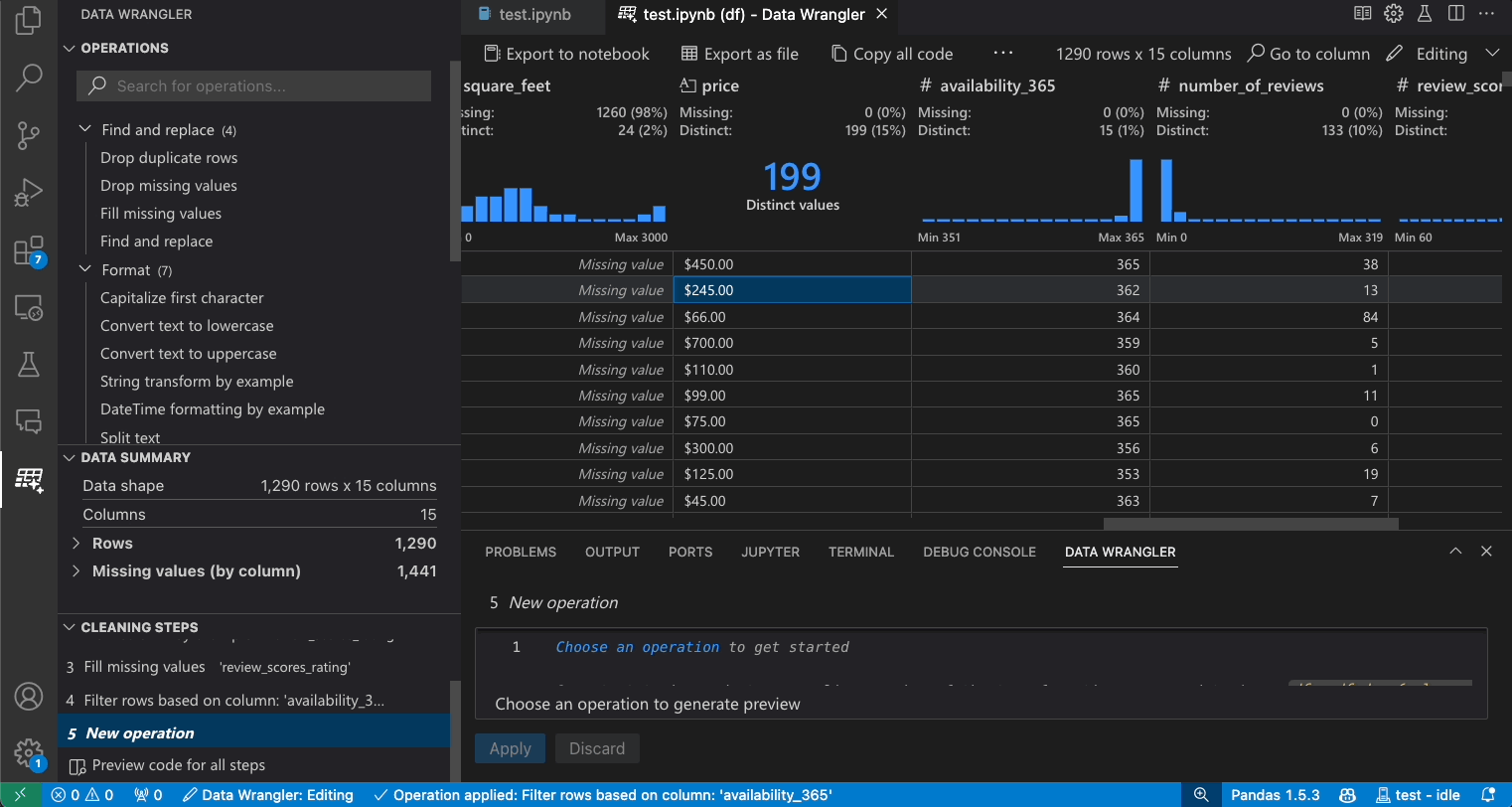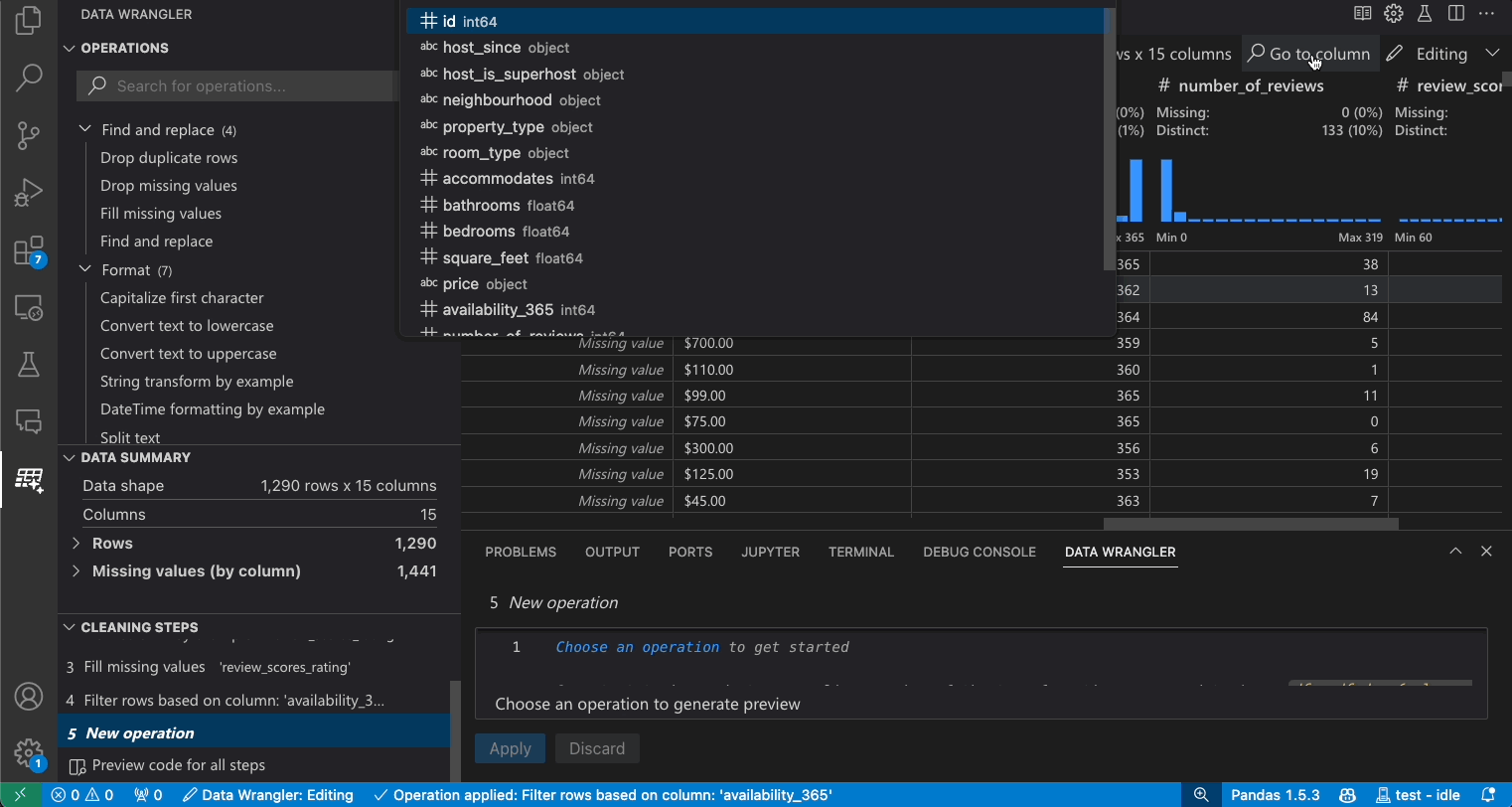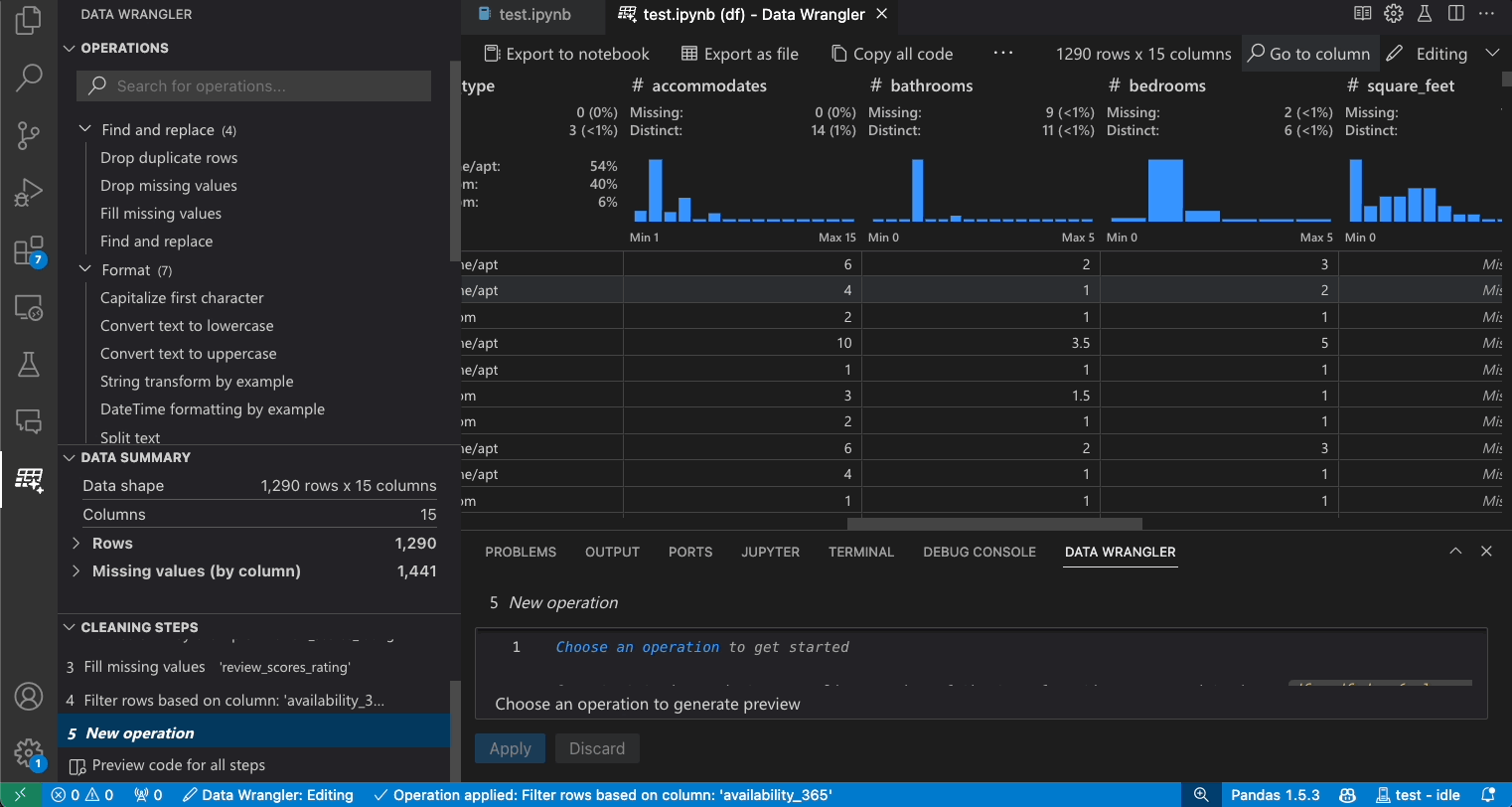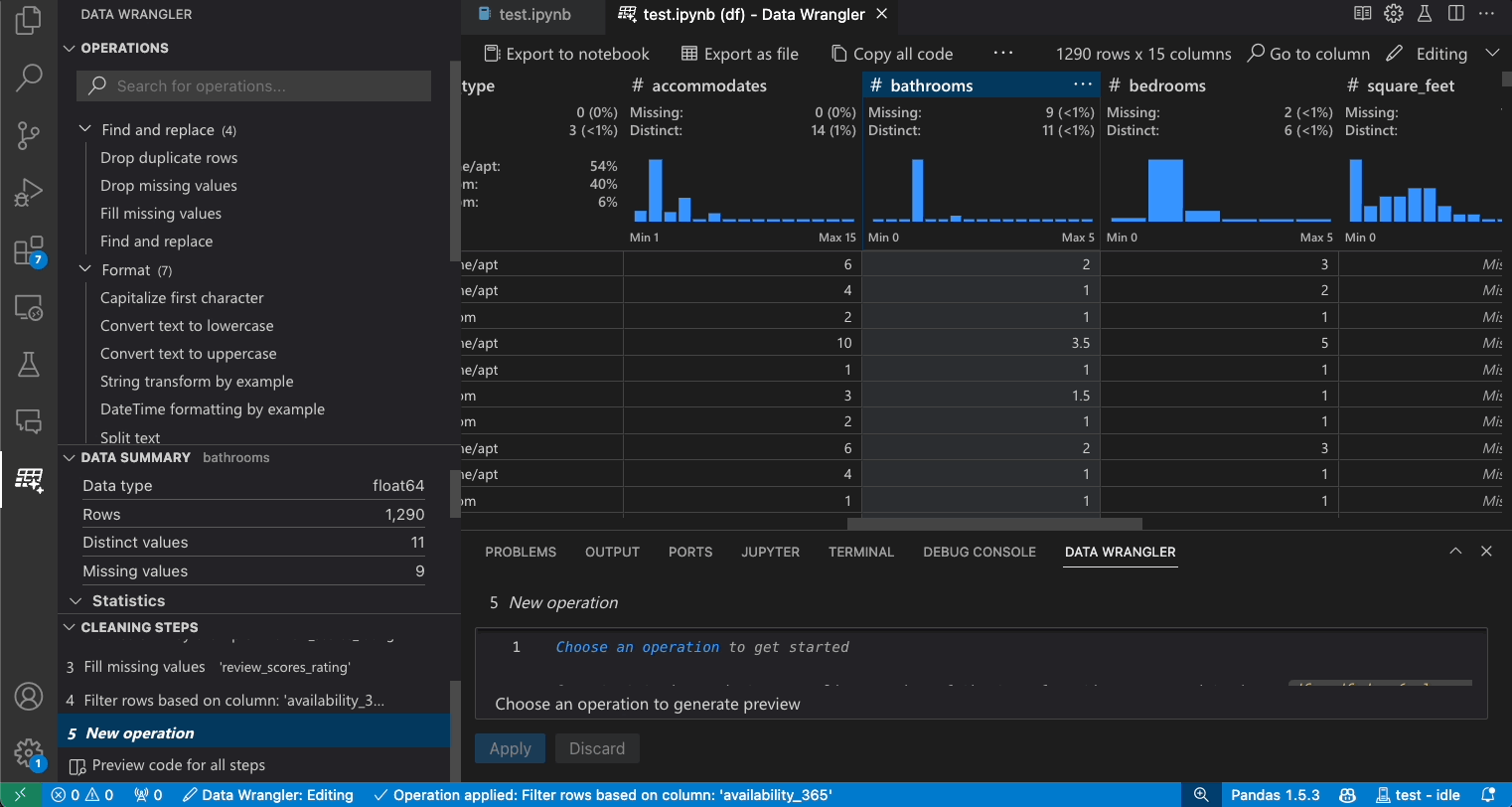
列の検索
データセット内の特定の列を見つけるには、Data Wrangler ツールバーから列へ移動を選択し、該当する列を検索します。
トラブルシューティング
一般的なカーネル接続の問題
一般的な接続の問題については、代替接続方法について上記の「Python カーネルへの接続」セクションを参照してください。ローカル Python インタープリターオプションに関連する問題をデバッグするには、Jupyter および Python 拡張機能の異なるバージョンをインストールする方法が問題解決につながる可能性があります。たとえば、拡張機能の安定版がインストールされている場合、プレリリース版 (またはその逆) をインストールするなどが考えられます。
すでにキャッシュされているカーネルをクリアするには、コマンドパレットから Data Wrangler: Clear cached runtime コマンドを実行できます ⇧⌘P (Windows、Linux Ctrl+Shift+P)。
データファイルを開くと UnicodeDecodeError が発生する
Data Wrangler からデータファイルを直接開くときに UnicodeDecodeError が発生した場合、これは2つの原因が考えられます。
- 開こうとしているファイルのエンコーディングが
UTF-8ではない - ファイルが破損している。
このエラーを回避するには、データファイルから直接開くのではなく、Jupyter Notebook から Data Wrangler を開く必要があります。Jupyter Notebook を使用して、Pandas でファイルを読み込みます。たとえば、read_csv メソッドを使用します。read メソッド内で、encoding および/または encoding_errors パラメータを使用して、使用するエンコーディングまたはエンコーディングエラーの処理方法を定義します。このファイルに適したエンコーディングがわからない場合は、chardet のようなライブラリを試して、動作するエンコーディングを推測することができます。
質問とフィードバック
問題が発生した場合、機能リクエストがある場合、またはその他のフィードバックがある場合は、GitHub リポジトリに Issue を提出してください: https://github.com/microsoft/vscode-data-wrangler/issues/new/choose
データとテレメトリ
Visual Studio Code 用 Microsoft Data Wrangler 拡張機能は、使用状況データを収集し、製品とサービスの改善に役立てるために Microsoft に送信します。詳細については、プライバシーに関する声明をお読みください。この拡張機能は telemetry.telemetryLevel 設定を尊重します。この設定の詳細については、https://vscode.dokyumento.jp/docs/configure/telemetry で確認できます。