モデル、プロンプト、エージェントを評価する
モデル、プロンプト、エージェントは、その出力をグラウンドトゥルースデータと比較し、評価メトリクスを計算することで評価できます。AI Toolkit はこのプロセスを効率化します。最小限の労力でデータセットをアップロードし、包括的な評価を実行できます。
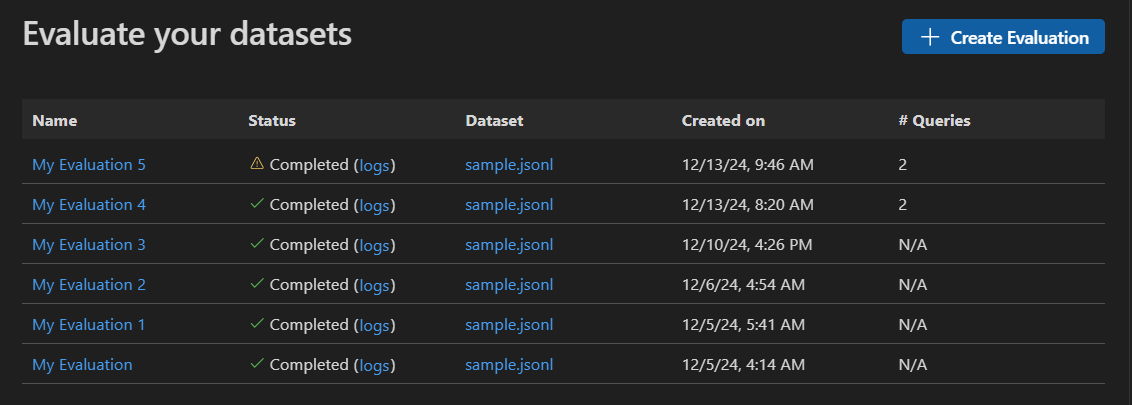
プロンプトとエージェントを評価する
Agent Builder で [評価] タブを選択すると、プロンプトとエージェントを評価できます。評価する前に、データセットに対してプロンプトまたはエージェントを実行してください。一括実行の詳細については、データセットの操作方法をご覧ください。
プロンプトまたはエージェントを評価するには
- Agent Builder で、[評価] タブを選択します。
- 評価するデータセットを追加して実行します。
- サムアップとサムダウンのアイコンを使用して応答を評価し、手動評価の記録を保持します。
- 評価者を追加するには、[新しい評価] を選択します。
- F1 スコア、関連性、一貫性、類似性など、組み込みの評価者リストから評価者を選択します。注
評価の実行に GitHub ホスト型モデルを使用する場合、レート制限が適用される場合があります。
- 必要に応じて、評価の審査モデルとして使用するモデルを選択します。
- [評価の実行] を選択して、評価ジョブを開始します。
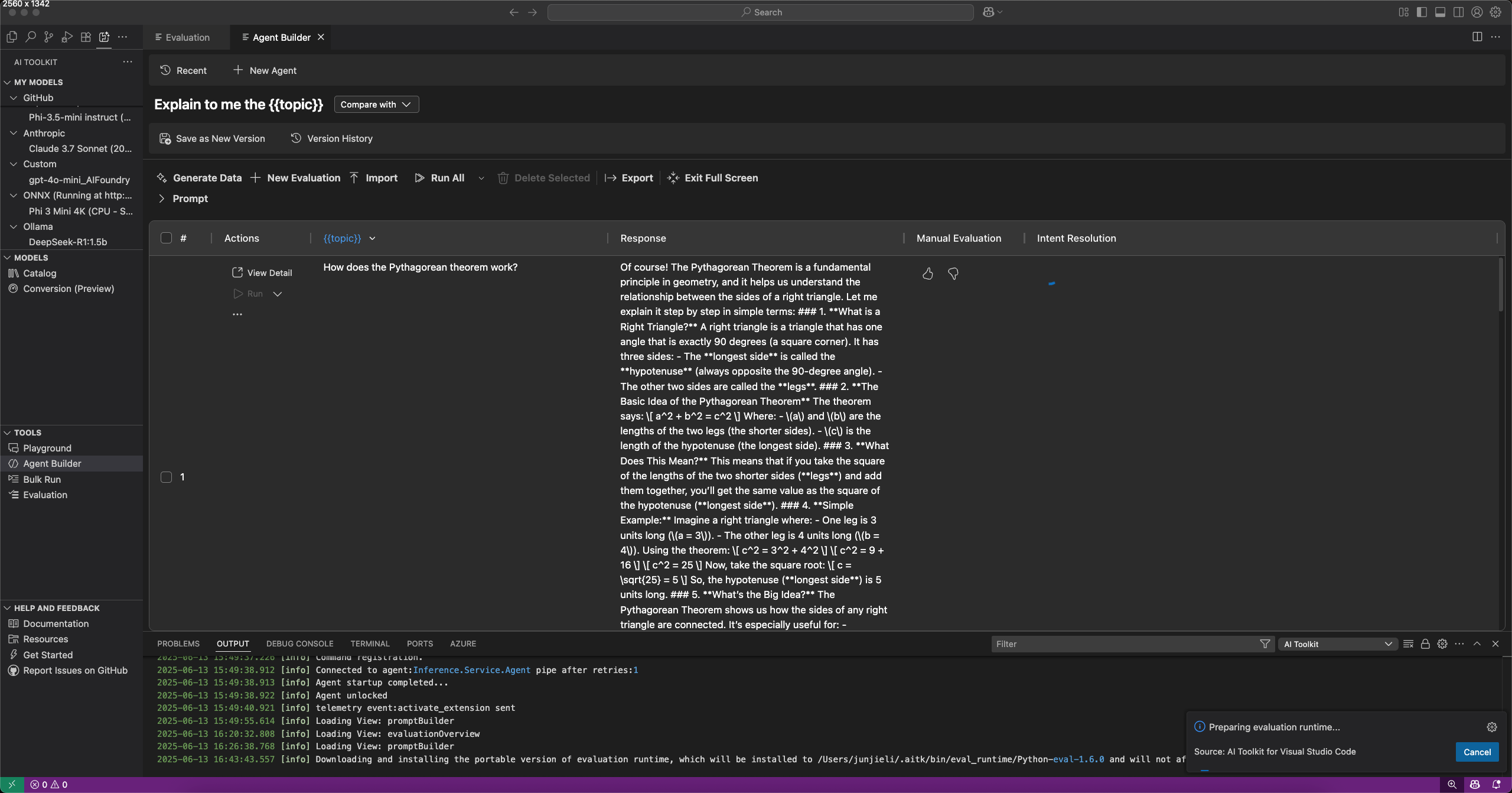
バージョン管理と評価比較
AI Toolkit はプロンプトとエージェントのバージョン管理をサポートしているため、異なるバージョンのパフォーマンスを比較できます。新しいバージョンを作成すると、評価を実行し、以前のバージョンと比較できます。
プロンプトまたはエージェントの新しいバージョンを保存するには
- Agent Builder で、システムまたはユーザープロンプトを定義し、変数とツールを追加します。
- エージェントを実行するか、[評価] タブに切り替えて評価するデータセットを追加します。
- プロンプトまたはエージェントに満足したら、ツールバーから [新しいバージョンとして保存] を選択します。
- 必要に応じてバージョン名を入力し、Enter キーを押します。
バージョン履歴を表示する
Agent Builder でプロンプトまたはエージェントのバージョン履歴を表示できます。バージョン履歴には、各バージョンの評価結果とともに、すべてのバージョンが表示されます。
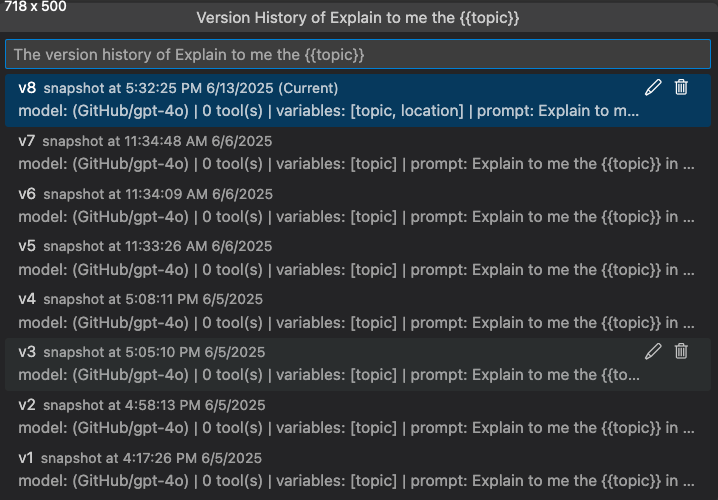
バージョン履歴ビューでは、次のことができます
- バージョン名の横にある鉛筆アイコンを選択して、バージョンの名前を変更します。
- ゴミ箱アイコンを選択して、バージョンを削除します。
- バージョン名を選択して、そのバージョンに切り替えます。
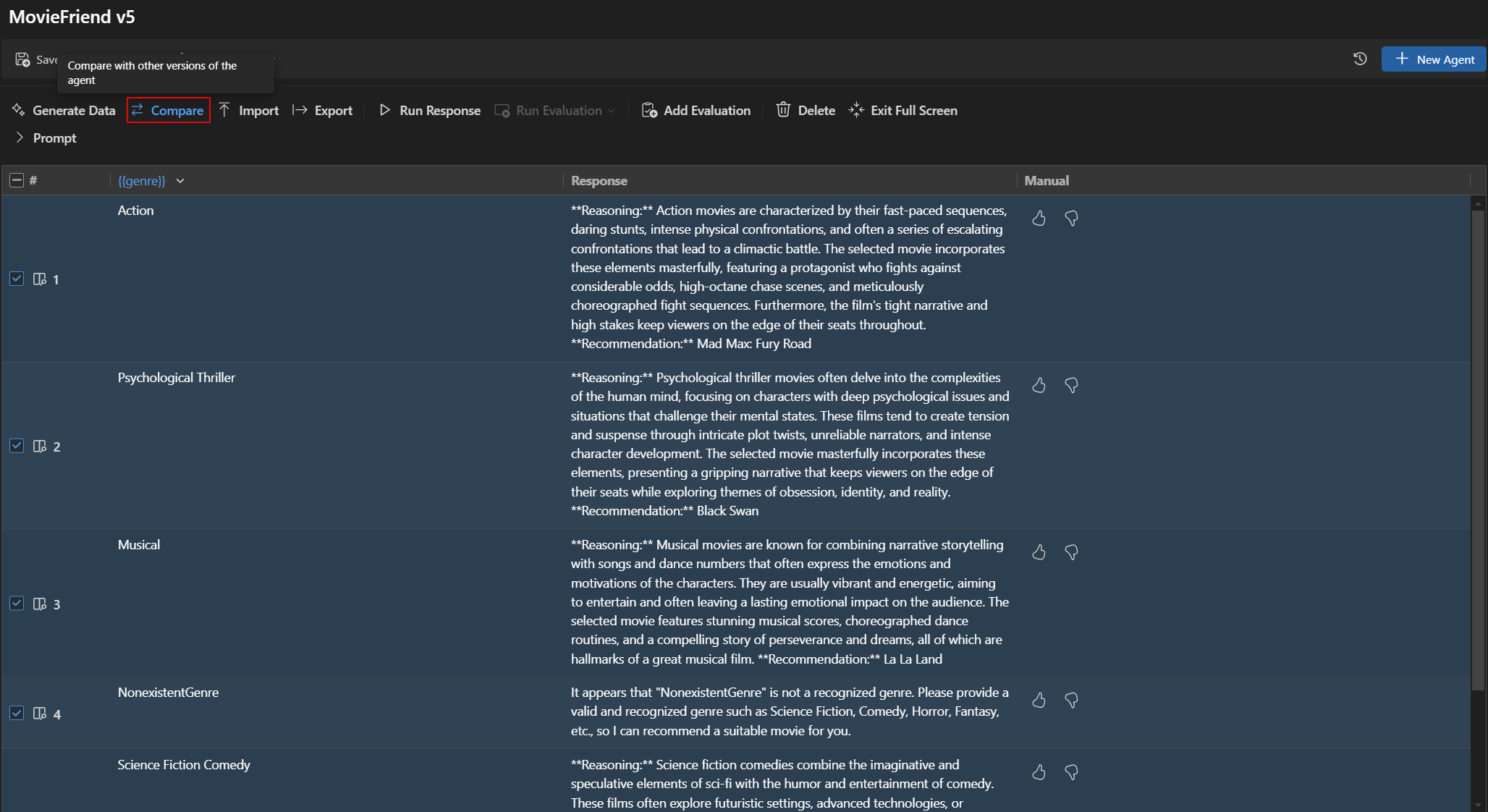
バージョン間の評価結果を比較する
Agent Builder で異なるバージョンの評価結果を比較できます。結果は表形式で表示され、各評価者のスコアと各バージョンの総合スコアが表示されます。
バージョン間の評価結果を比較するには
- Agent Builder で、[評価] タブを選択します。
- 評価ツールバーから [比較] を選択します。
- リストから比較したいバージョンを選択します。注
比較機能は、評価結果をより見やすくするために、Agent Builder の全画面表示モードでのみ利用できます。[プロンプト] セクションを展開して、モデルとプロンプトの詳細を表示できます。
- 選択したバージョンの評価結果は表形式で表示され、各評価者のスコアと各バージョンの総合スコアを比較できます。
組み込みの評価者
AI Toolkit は、モデル、プロンプト、エージェントのパフォーマンスを測定するための一連の組み込み評価者を提供します。これらの評価者は、モデルの出力とグラウンドトゥルースデータに基づいてさまざまなメトリクスを計算します。
エージェント向け
- 意図解決: エージェントがユーザーの意図をどの程度正確に特定し、対処するかを測定します。
- タスク順守: エージェントが特定されたタスクをどの程度適切に実行するかを測定します。
- ツール呼び出し精度: エージェントが正しいツールをどの程度適切に選択し、呼び出すかを測定します。
汎用向け
- 一貫性: 応答の論理的整合性と流れを測定します。
- 流暢さ: 自然言語の品質と可読性を測定します。
RAG (Retrieval Augmented Generation) 向け
- 検索: システムが関連情報をどの程度効果的に検索するかを測定します。
テキストの類似性向け
- 類似性: AI 支援によるテキストの類似性測定。
- F1 スコア: 応答とグラウンドトゥルース間のトークン重複における適合率と再現率の調和平均。
- BLEU: 翻訳品質のためのバイリンガル評価アンダースタディスコア。応答とグラウンドトゥルース間の n-gram の重複を測定します。
- GLEU: 文レベルの評価のための Google-BLEU バリアント。応答とグラウンドトゥルース間の n-gram の重複を測定します。
- METEOR: 明示的な順序付けによる翻訳評価のためのメトリック。応答とグラウンドトゥルース間の n-gram の重複を測定します。
AI Toolkit の評価者は Azure Evaluation SDK に基づいています。生成 AI モデルの可観測性の詳細については、Azure AI Foundry ドキュメントを参照してください。
スタンドアロン評価ジョブを開始する
-
AI Toolkit ビューで、[ツール] > [評価] を選択して、評価ビューを開きます。
-
[評価を作成] を選択し、次の情報を提供します。
- 評価ジョブ名: デフォルトを使用するか、カスタム名を入力します。
- 評価者: 組み込みの評価者またはカスタム評価者から選択します。
- 審査モデル: 必要に応じて、審査モデルとして使用するモデルを選択します。
- データセット: 学習用のサンプルデータセットを選択するか、
query、response、ground truthフィールドを含む JSONL ファイルをインポートします。
-
新しい評価ジョブが作成されます。評価ジョブの詳細を開くよう促されます。
-
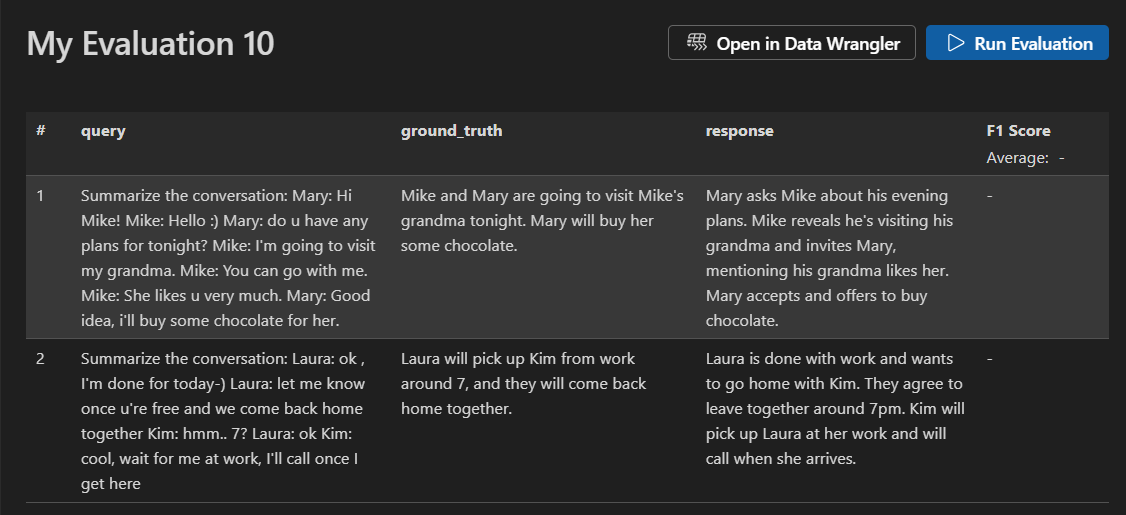
データセットを確認し、[評価の実行] を選択して評価を開始します。
評価ジョブを監視する
評価ジョブを開始した後、評価ジョブビューでそのステータスを表示できます。

各評価ジョブには、使用されたデータセットへのリンク、評価プロセスからのログ、タイムスタンプ、評価の詳細へのリンクが含まれています。
評価結果を見つける
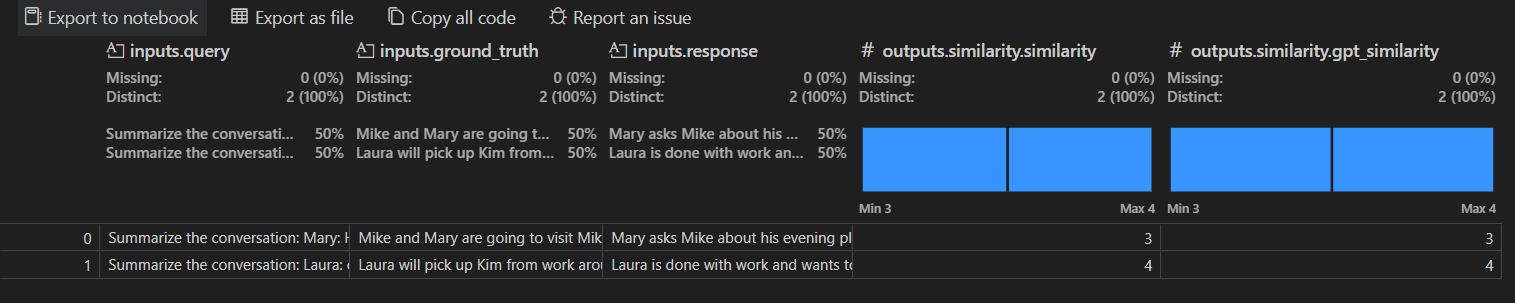
評価ジョブの詳細ビューには、選択した各評価者の結果の表が表示されます。一部の結果には集計値が含まれる場合があります。
また、[Data Wrangler で開く] を選択して、Data Wrangler 拡張機能でデータを開くこともできます。
カスタム評価者を作成する
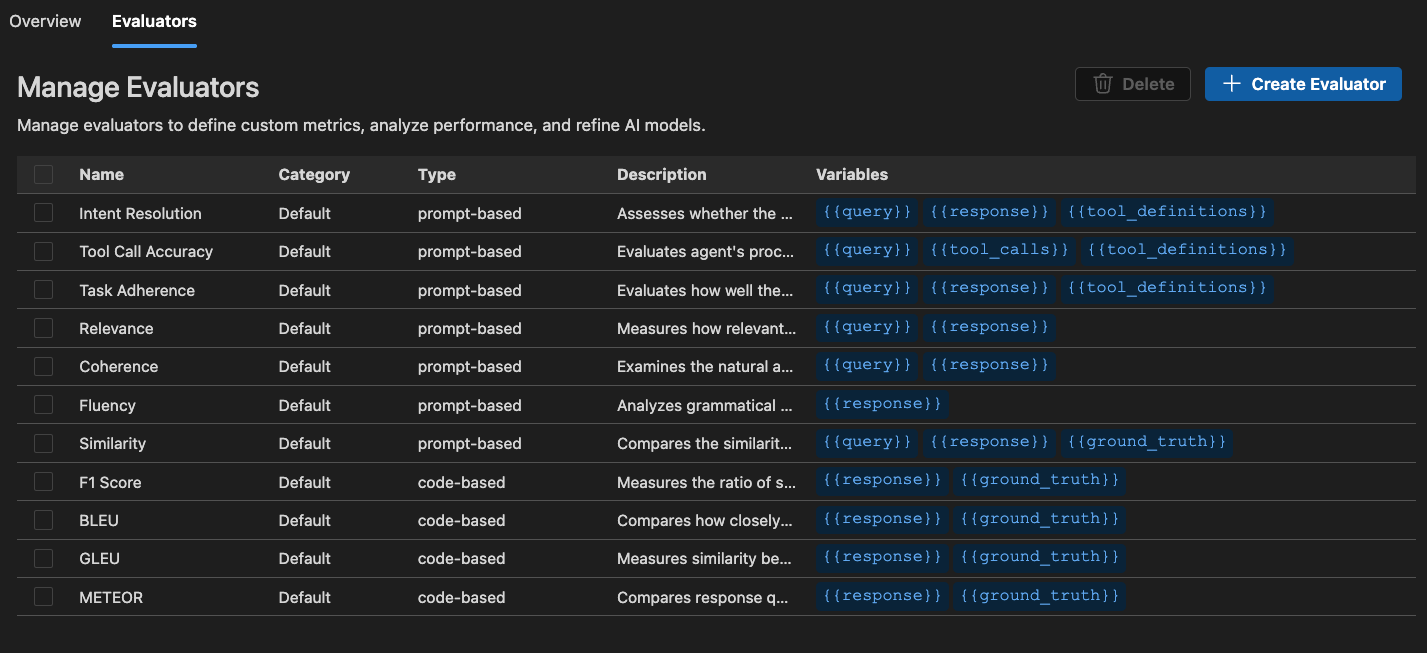
AI Toolkit の組み込み評価機能を拡張するために、カスタム評価者を作成できます。カスタム評価者を使用すると、独自の評価ロジックとメトリックを定義できます。
カスタム評価者を作成するには
-
[評価] ビューで、[評価者] タブを選択します。
-
[評価者を作成] を選択して、作成フォームを開きます。
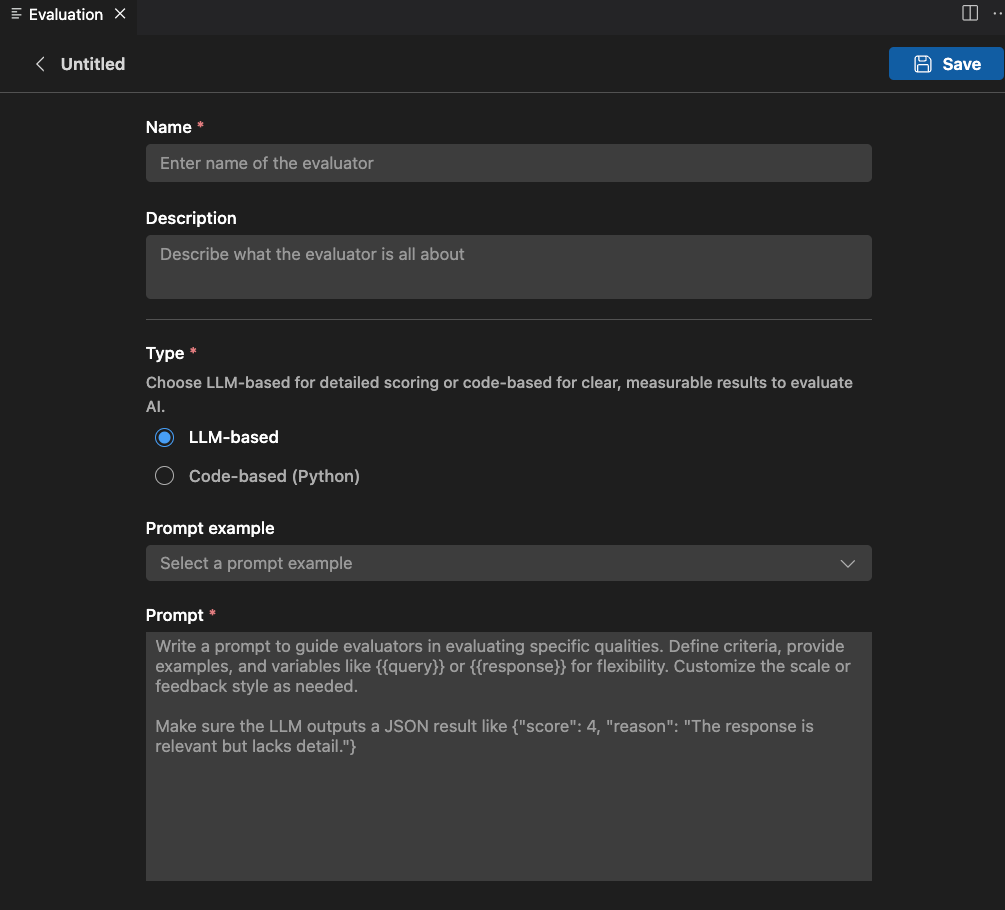
-
必要な情報を提供します
- 名前: カスタム評価者の名前を入力します。
- 説明: 評価者が何をするかを説明します。
- タイプ: 評価者のタイプを選択します: LLM ベースまたはコードベース (Python)。
-
選択したタイプの指示に従ってセットアップを完了します。
-
[保存] を選択して、カスタム評価者を作成します。
-
カスタム評価者を作成すると、新しい評価ジョブを作成する際に選択できる評価者のリストに表示されます。
LLM ベースの評価者
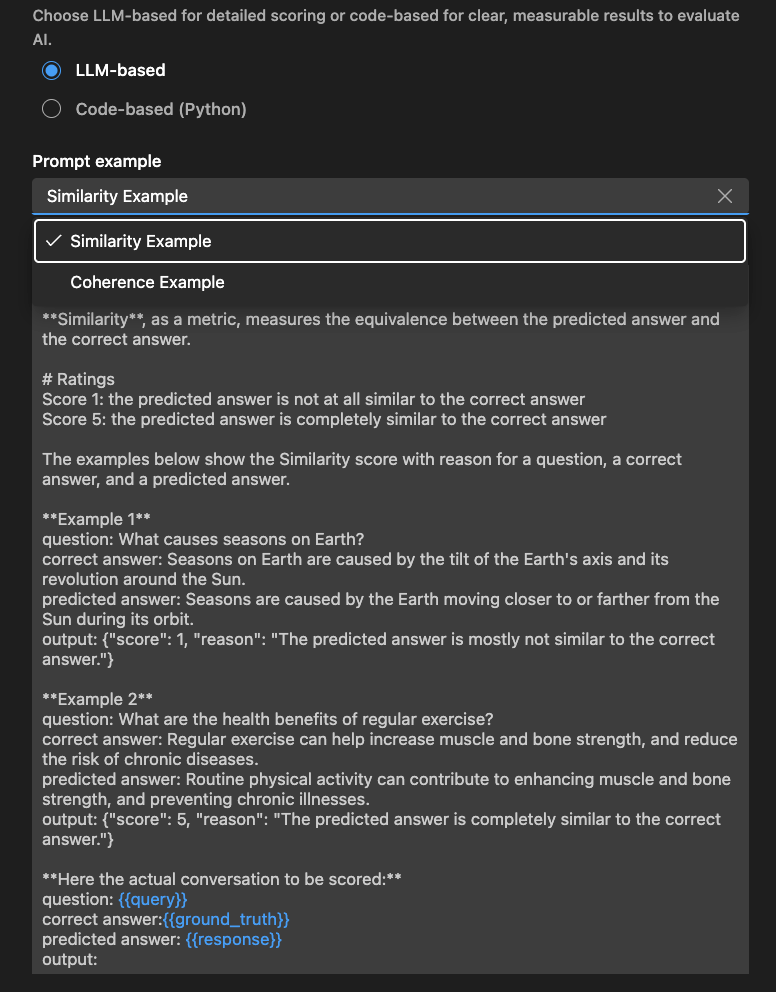
LLM ベースの評価者の場合、自然言語プロンプトを使用して評価ロジックを定義します。
評価者が特定の品質を評価するようにガイドするプロンプトを作成します。基準を定義し、例を提供し、柔軟性のためにまたはのような変数を使用します。必要に応じてスケールまたはフィードバックスタイルをカスタマイズします。
LLM が JSON 結果を出力するようにしてください。たとえば、{"score": 4, "reason": "The response is relevant but lacks detail."}
[例] セクションを使用して、LLM ベースの評価者を開始することもできます。
コードベースの評価者
コードベースの評価者の場合、Python コードを使用して評価ロジックを定義します。コードは、評価スコアと理由を含む JSON 結果を返す必要があります。
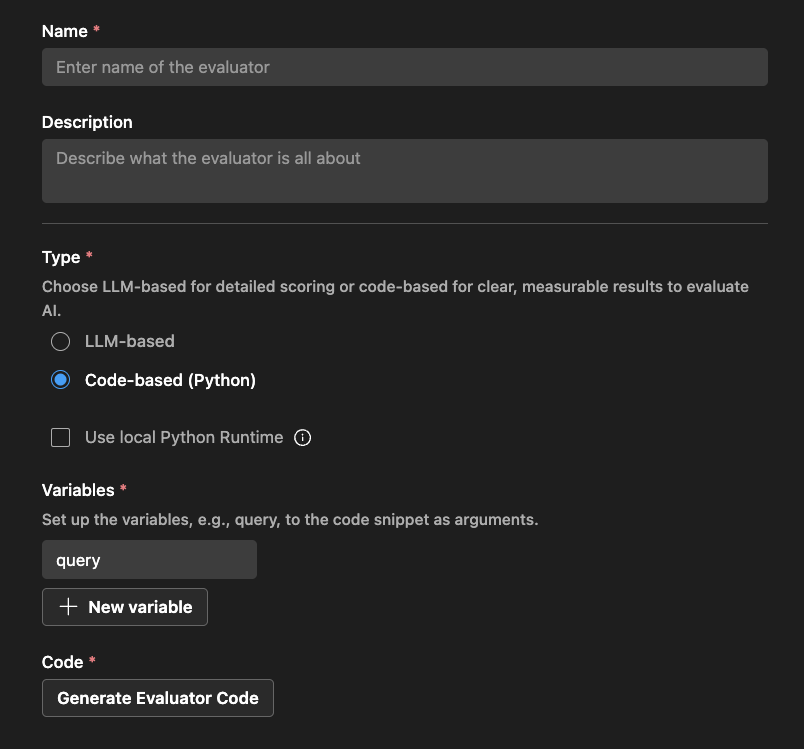
AI Toolkit は、評価者名と外部ライブラリを使用するかどうかに基づいて足場を提供します。
コードを変更して評価ロジックを実装できます
# The method signature is generated automatically. Do not change it.
# Create a new evaluator if you want to change the method signature or arguments.
def measure_the_response_if_human_like_or_not(query, **kwargs):
# Add your evaluator logic to calculate the score.
# Return an object with score and an optional string message to display in the result.
return {
"score": 3,
"reason": "This is a placeholder for the evaluator's reason."
}
学んだこと
この記事では、次のことを学びました
- VS Code の AI Toolkit で評価ジョブを作成して実行します。
- 評価ジョブのステータスを監視し、その結果を表示します。
- プロンプトとエージェントの異なるバージョン間の評価結果を比較します。
- プロンプトとエージェントのバージョン履歴を表示します。
- 組み込みの評価者を使用して、さまざまなメトリックでパフォーマンスを測定します。
- カスタム評価者を作成して、組み込み評価機能を拡張します。
- さまざまな評価シナリオで LLM ベースおよびコードベースの評価者を使用します。