テキストバッファの再実装
2018年3月23日 Peng Lyu、@njukidreborn
Visual Studio Code 1.21リリースには、速度とメモリ使用量の両面でパフォーマンスが大幅に向上した、まったく新しいテキストバッファ実装が含まれています。このブログ記事では、これらの改善につながったデータ構造とアルゴリズムをどのように選択し、設計したかについて説明したいと思います。
JavaScriptプログラムに関するパフォーマンスの議論では、通常、どの程度をネイティブコードで実装すべきかという議論が伴います。VS Codeのテキストバッファの場合、これらの議論は1年以上前に始まりました。詳細な調査の結果、テキストバッファのC++実装はメモリを大幅に節約できることが判明しましたが、期待していたパフォーマンス向上は見られませんでした。カスタムのネイティブ表現とV8の文字列の間で文字列を変換することはコストがかかり、私たちのケースでは、C++でテキストバッファ操作を実装することによって得られたパフォーマンスを損なってしまいました。これについては、本投稿の最後で詳しく説明します。
ネイティブコードに移行しないため、JavaScript/TypeScriptコードを改善する方法を見つける必要がありました。Vyacheslav Egorovによるこの記事のような示唆に富むブログ記事は、JavaScriptエンジンを限界まで追い込み、可能な限り最高のパフォーマンスを引き出す方法を示しています。低レベルなエンジントリックを使わなくても、より適切なデータ構造とより高速なアルゴリズムを使用することで、1桁以上速度を向上させることは可能です。
以前のテキストバッファデータ構造
エディタのメンタルモデルは行ベースです。開発者はソースコードを行ごとに読み書きし、コンパイラは行/列ベースの診断を提供し、スタックトレースには行番号が含まれ、トークン化エンジンは行ごとに実行されます。単純ではありますが、VS Codeを支えるテキストバッファの実装は、Monacoプロジェクトを開始した最初の日からほとんど変わっていませんでした。私たちは行の配列を使用しており、典型的なテキストドキュメントは比較的小さいため、これはかなりうまく機能していました。ユーザーが入力すると、配列内で変更する行を見つけて置き換えました。新しい行を挿入すると、新しい行オブジェクトを行配列にスプライスし、JavaScriptエンジンがその大変な作業を私たちに代わって行いました。
しかし、特定のファイルを開くとVS Codeでメモリ不足エラーが発生するという報告が届き続けていました。例えば、あるユーザーは35MBのファイルを開くことができませんでした。根本原因は、そのファイルが行数が多すぎたこと、つまり1370万行でした。各行に対してModelLineオブジェクトを作成し、各オブジェクトは約40~60バイトを使用するため、行配列はドキュメントを格納するために約600MBのメモリを使用しました。これは、元のファイルサイズの約20倍にもなります!
行配列表現のもう一つの問題は、ファイルを開く速度でした。行の配列を構築するために、改行でコンテンツを分割する必要があり、これにより各行ごとに文字列オブジェクトが得られました。この分割自体がパフォーマンスを低下させることは、後述のベンチマークで確認できます。
新しいテキストバッファ実装の検討
古い行配列表現は、作成に時間がかかり、多くのメモリを消費しますが、行の検索は高速です。理想的な世界では、ファイルのテキストのみを保存し、追加のメタデータは一切保存しません。そこで、メタデータが少ないデータ構造を探し始めました。様々なデータ構造を検討した結果、ピーステーブルが開始点として良い候補であることに気づきました。
ピーステーブルを使用してメタデータを削減する
ピーステーブルは、テキストドキュメント(TypeScriptのソースコード)に対する一連の編集を表すために使用されるデータ構造です。
class PieceTable {
original: string; // original contents
added: string; // user added contents
nodes: Node[];
}
class Node {
type: NodeType;
start: number;
length: number;
}
enum NodeType {
Original,
Added
}
ファイルが最初にロードされると、ピーステーブルはファイルの内容全体を`original`フィールドに含みます。`added`フィールドは空です。`NodeType.Original`型の単一のノードがあります。ユーザーがファイルの末尾に入力すると、新しいコンテンツが`added`フィールドに追加され、ノードリストの最後に`NodeType.Added`型の新しいノードが挿入されます。同様に、ユーザーがノードの中央で編集を行うと、そのノードが分割され、必要に応じて新しいノードが挿入されます。
下の動画は、ピーステーブル構造でドキュメントを行ごとにアクセスする方法を示しています。2つのバッファ (`original` と `added`) と3つのノードがあります (これは `original` コンテンツの途中に挿入があったために発生します)。
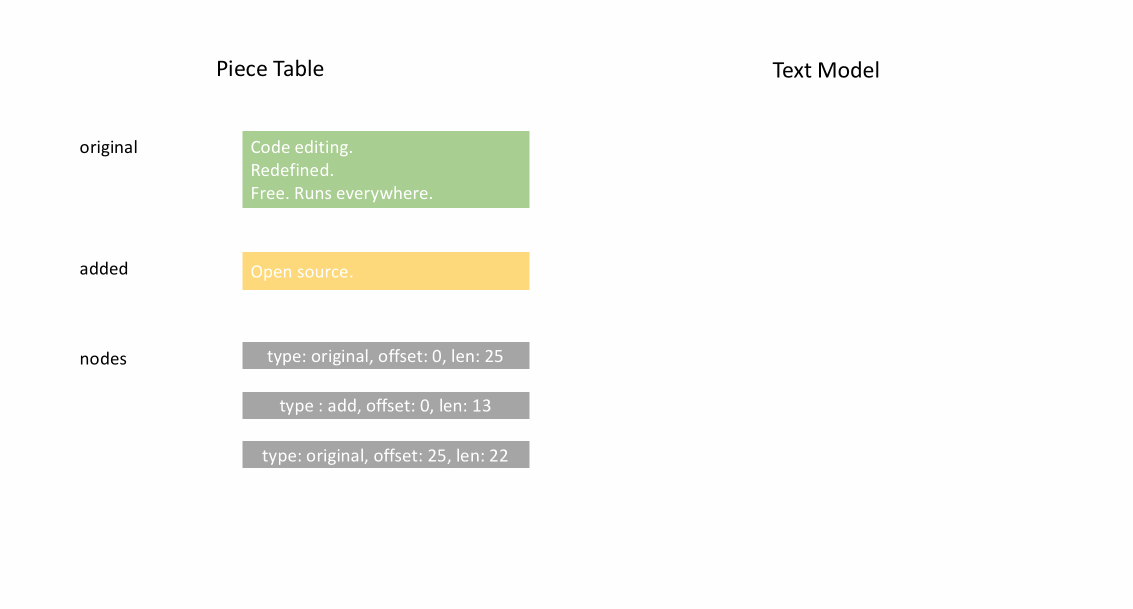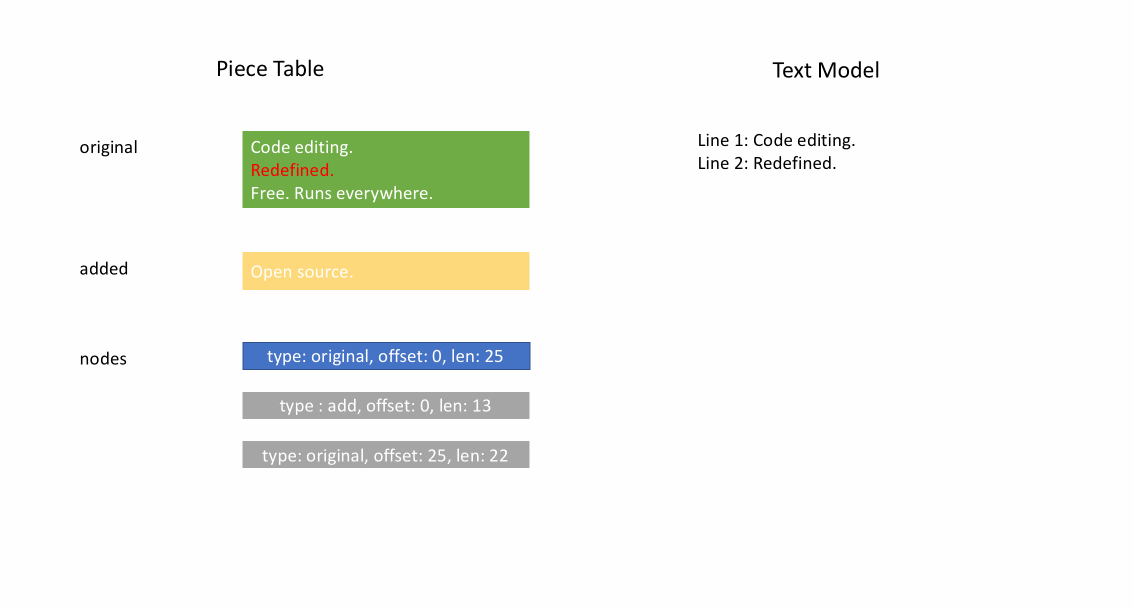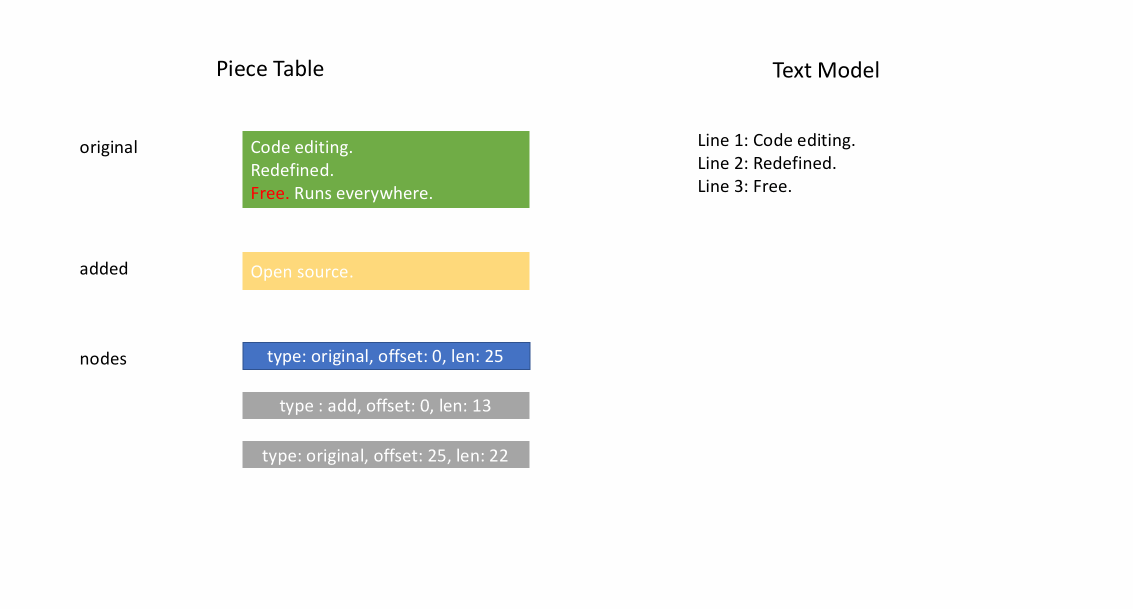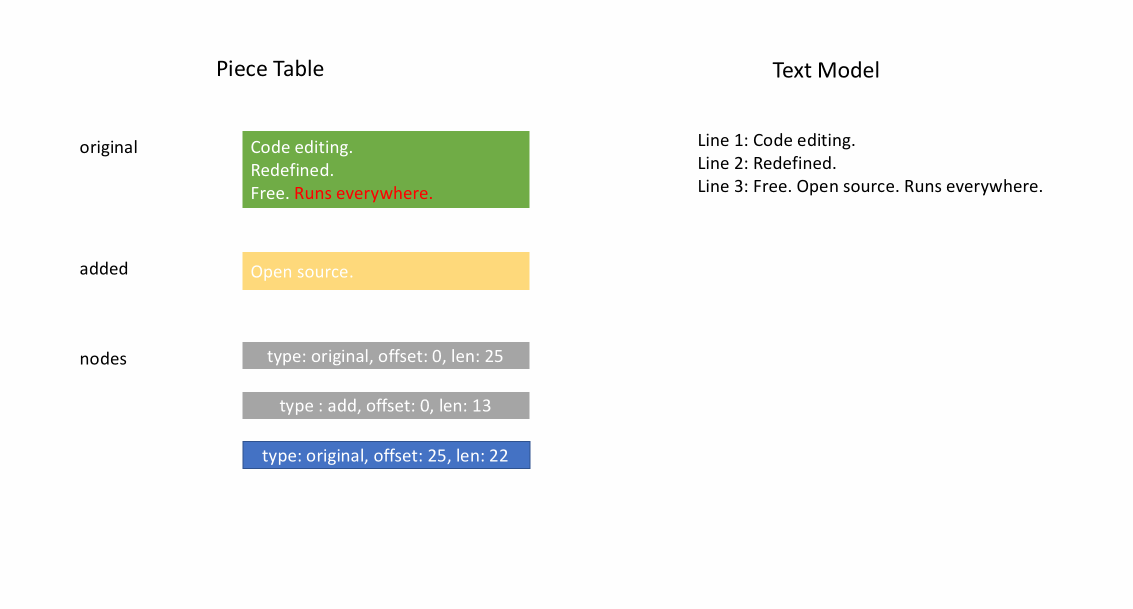
ピーステーブルの初期メモリ使用量はドキュメントのサイズに近く、変更に必要なメモリは編集と追加されたテキストの量に比例します。そのため、通常、ピーステーブルはメモリを効率的に使用します。しかし、メモリ使用量が少ない代償として、論理行へのアクセスは遅くなります。例えば、1000行目のコンテンツを取得したい場合、ドキュメントの先頭からすべての文字を繰り返し、最初の999個の改行を見つけ、次の改行まで各文字を読み込むという方法しかありません。
より高速な行検索のためのキャッシングの利用
従来のピーステーブルノードにはオフセットしか含まれていませんが、行の内容検索を高速化するために改行情報を追加できます。改行位置を格納する直感的な方法は、ノードのテキスト内で検出された各改行のオフセットを格納することです。
class PieceTable {
original: string;
added: string;
nodes: Node[];
}
class Node {
type: NodeType;
start: number;
length: number;
lineStarts: number[];
}
enum NodeType {
Original,
Added
}
例えば、特定の`Node`インスタンスの2行目にアクセスしたい場合、`node.lineStarts[0]`と`node.lineStarts[1]`を読み取ることで、行が始まる相対オフセットと終わる相対オフセットが得られます。ノードがいくつの改行を持っているかを知っているので、ドキュメント内の任意の行にアクセスするのは簡単です。最初のノードから目的の改行が見つかるまで各ノードを読み取ります。
アルゴリズムはシンプルであり、文字ごとに反復するのではなく、テキストのチャンク全体を飛び越えることができるようになったため、以前よりも優れた動作をします。後でさらに改善できることがわかります。
文字列連結の罠を回避する
ピーステーブルは、ディスクから読み込まれた元のコンテンツ用と、ユーザー編集用の2つのバッファを保持します。VS Codeでは、Node.jsの`fs.readFile`を使用してテキストファイルを読み込み、64KBのチャンクでコンテンツを配信します。そのため、ファイルが例えば64MBと大きい場合、1000個のチャンクを受け取ることになります。すべてのチャンクを受け取った後、それらを1つの大きな文字列に連結し、ピーステーブルの`original`フィールドに保存することができます。
V8が邪魔をするまでは、これは妥当なことのように聞こえます。私は500MBのファイルを開こうとして例外を受け取りました。私が使用していたV8のバージョンでは、最大文字列長が256MBだったためです。この制限は将来のV8バージョンでは1GBに引き上げられますが、それでも問題は完全に解決されません。
`original`と`added`のバッファを保持する代わりに、バッファのリストを保持することができます。このリストを短く保つこともできますし、`fs.readFile`から返されるものからヒントを得て、文字列の連結を一切避けることもできます。ディスクから64KBのチャンクを受け取るたびに、それを直接`buffers`配列にプッシュし、このバッファを指すノードを作成します。
class PieceTable {
buffers: string[];
nodes: Node[];
}
class Node {
bufferIndex: number;
start: number; // start offset in buffers[bufferIndex]
length: number;
lineStarts: number[];
}
バランスの取れた二分木を使用して行検索を高速化する
文字列連結を回避することで、大きなファイルを開くことができるようになりましたが、これにより別の潜在的なパフォーマンス問題が発生します。例えば64MBのファイルをロードすると、ピーステーブルには1000個のノードができます。各ノードに改行位置がキャッシュされていても、どのノードに絶対行番号があるかはわかりません。行の内容を取得するには、その行を含むノードが見つかるまで、すべてのノードをたどる必要があります。この例では、探している行番号に応じて、最大1000個のノードを反復処理する必要があります。したがって、最悪の場合の時間計算量はO(N)(Nはノード数)です。
各ノードに絶対行番号をキャッシュし、ノードのリストに対して二分探索を使用すると、検索速度が向上しますが、ノードを変更するたびに、後続のすべてのノードを訪れて行番号の差分を適用する必要があります。これは避けたいことですが、二分探索のアイデアは良いものです。同じ効果を達成するために、平衡二分木を活用できます。
これで、ツリーノードを比較するためのキーとしてどのようなメタデータを使用すべきかを決定する必要があります。すでに述べたように、ドキュメント内のノードのオフセットまたは絶対行番号を使用すると、編集操作の時間計算量がO(N)になります。O(log n)の時間計算量を望む場合、ツリーノードのサブツリーのみに関連する何かが必要です。したがって、ユーザーがテキストを編集すると、変更されたノードのメタデータを再計算し、そのメタデータの変更を親ノードに沿ってルートまで伝播させます。
`Node`が4つのプロパティ(`bufferIndex`、`start`、`length`、`lineStarts`)しか持たない場合、結果を見つけるのに数秒かかります。より高速にするには、ノードの左サブツリーのテキスト長と改行数も格納できます。このようにすると、ツリーのルートからオフセットまたは行番号で検索することが効率的になります。右サブツリーのメタデータを格納することも同じですが、両方をキャッシュする必要はありません。
クラスは次のようになります
class PieceTable {
buffers: string[];
rootNode: Node;
}
class Node {
bufferIndex: number;
start: number;
length: number;
lineStarts: number[];
left_subtree_length: number;
left_subtree_lfcnt: number;
left: Node;
right: Node;
parent: Node;
}
さまざまな種類の平衡二分木の中から、我々は赤黒木を選択しました。これは、より「編集」に適しているからです。
オブジェクトの割り当てを削減する
各ノードに行区切りオフセットを格納すると仮定します。ノードを変更するたびに、行区切りオフセットを更新する必要があるかもしれません。たとえば、999個の行区切りを含むノードがあり、`lineStarts`配列が1000個の要素を持つとします。ノードを均等に分割すると、それぞれ約500個の要素を含む2つの配列を持つ2つのノードが作成されます。リニアなメモリ空間で直接操作しているわけではないため、配列を2つに分割することはポインタを移動するよりもコストがかかります。
良いニュースは、ピーステーブル内のバッファは読み取り専用(オリジナルバッファ)か追記専用(変更されたバッファ)のいずれかであるため、バッファ内の改行は移動しないことです。`Node`は対応するバッファ上の改行オフセットへの2つの参照を保持するだけで済みます。作業が少なければ少ないほど、パフォーマンスは向上します。私たちのベンチマークでは、この変更を適用することで、実装におけるテキストバッファ操作が3倍高速になることが示されました。実際の実装については後述します。
class Buffer {
value: string;
lineStarts: number[];
}
class BufferPosition {
index: number; // index in Buffer.lineStarts
remainder: number;
}
class PieceTable {
buffers: Buffer[];
rootNode: Node;
}
class Node {
bufferIndex: number;
start: BufferPosition;
end: BufferPosition;
...
}
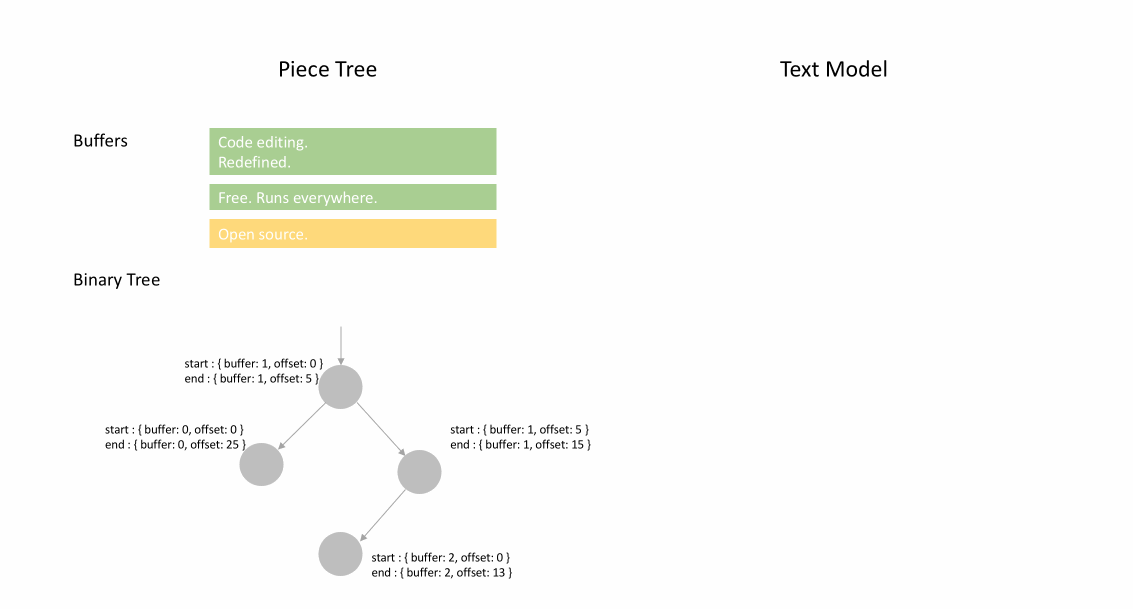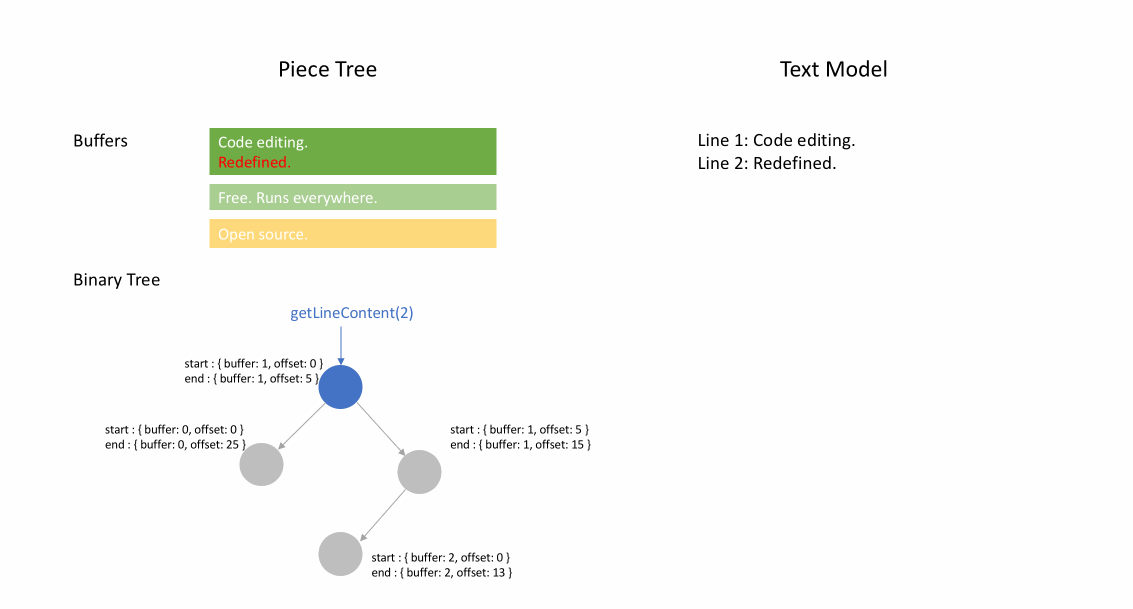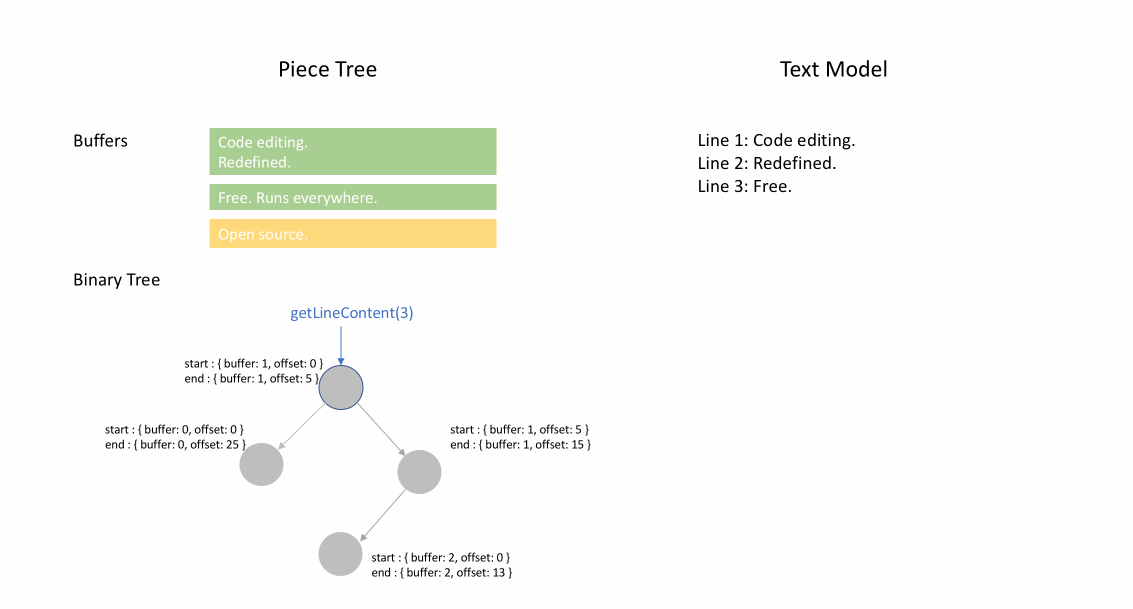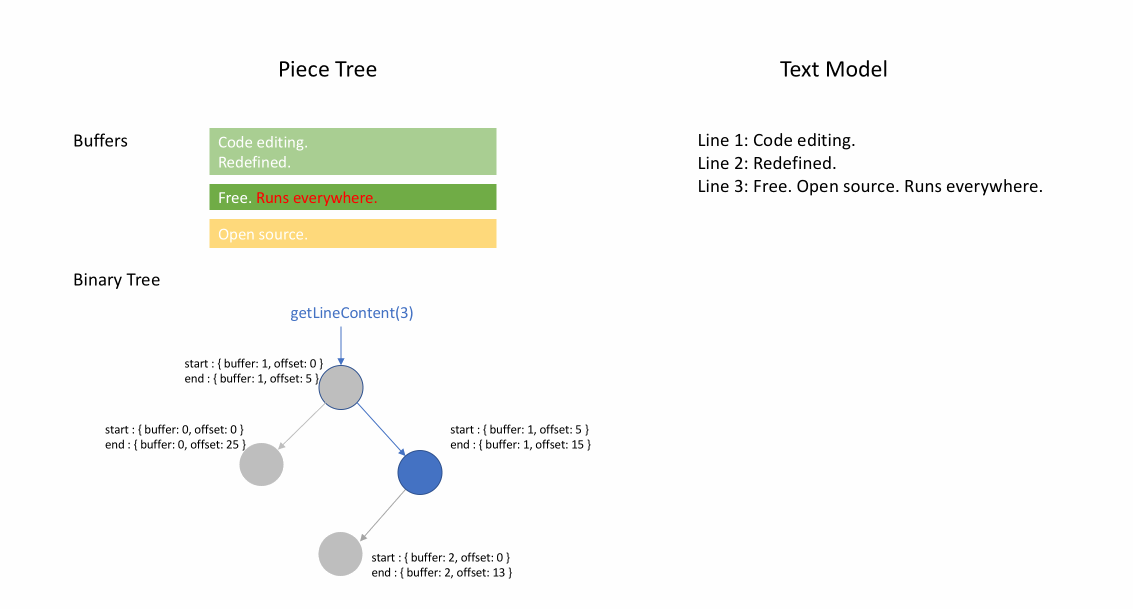
ピースツリー
このテキストバッファを**「ラインモデルに最適化された、赤黒木を持つ複数のバッファピーステーブル」**と呼びたいです。しかし、毎日のスタンディングミーティングで、誰もが自分のやったことを共有する時間が90秒に制限されているときに、この長い名前を何度も繰り返すのは賢明ではありません。そこで、単に**「ピースツリー」**と呼び始めました。これが何であるかを反映しています。
このデータ構造の理論的な理解は一つですが、実世界でのパフォーマンスは別の話です。使用する言語、コードが実行される環境、クライアントがAPIを呼び出す方法、その他の要因が結果に大きく影響する可能性があります。ベンチマークは包括的な情報を提供できるため、元の行配列実装とピースツリー実装に対して、小・中・大ファイルでベンチマークを実行しました。
準備
結果を伝えるために、オンラインで現実的なファイルを探しました。
- checker.ts - 1.46 MB, 26k 行。
- sqlite.c - 4.31MB, 128k 行。
- ロシア語-英語バイリンガル辞書 - 14MB, 552k 行。
そして、いくつかの大きなファイルを手動で作成しました。
- 新しく開いたVS Code InsiderのChromiumヒープスナップショット - 54MB, 3M行。
- checker.ts X 128 - 184MB, 3M行。
1. メモリ使用量
ロード直後のピースツリーのメモリ使用量は、元のファイルサイズに非常に近く、古い実装よりも大幅に低い。最初のラウンドはピースツリーの勝ちです。
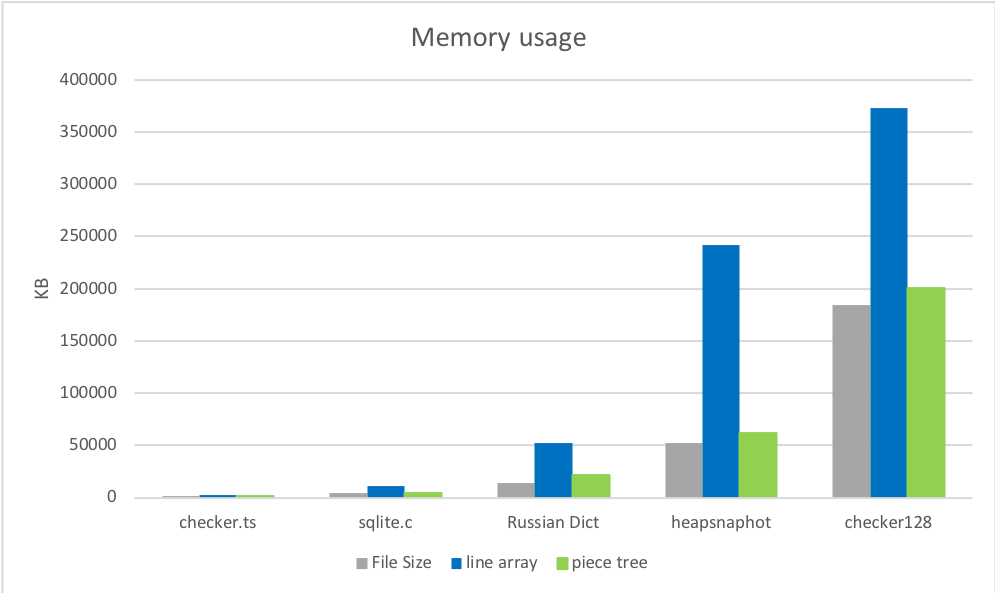
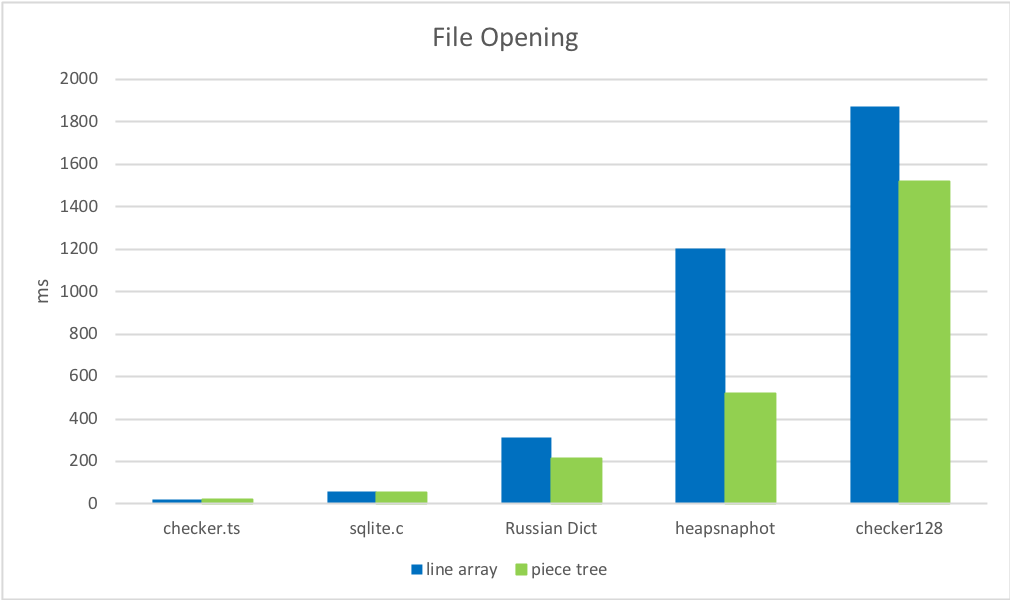
2. ファイルオープン時間
改行を見つけてキャッシュする方が、ファイルを文字列の配列に分割するよりもはるかに高速です。
3. 編集
2つのワークフローをシミュレートしました。
- ドキュメント内のランダムな位置での編集。
- 連続した入力。
この2つのシナリオを模倣しようとしました。ドキュメントに1000回のランダムな編集または1000回の連続挿入を適用し、各テキストバッファがどれくらいの時間を必要とするかを確認します。
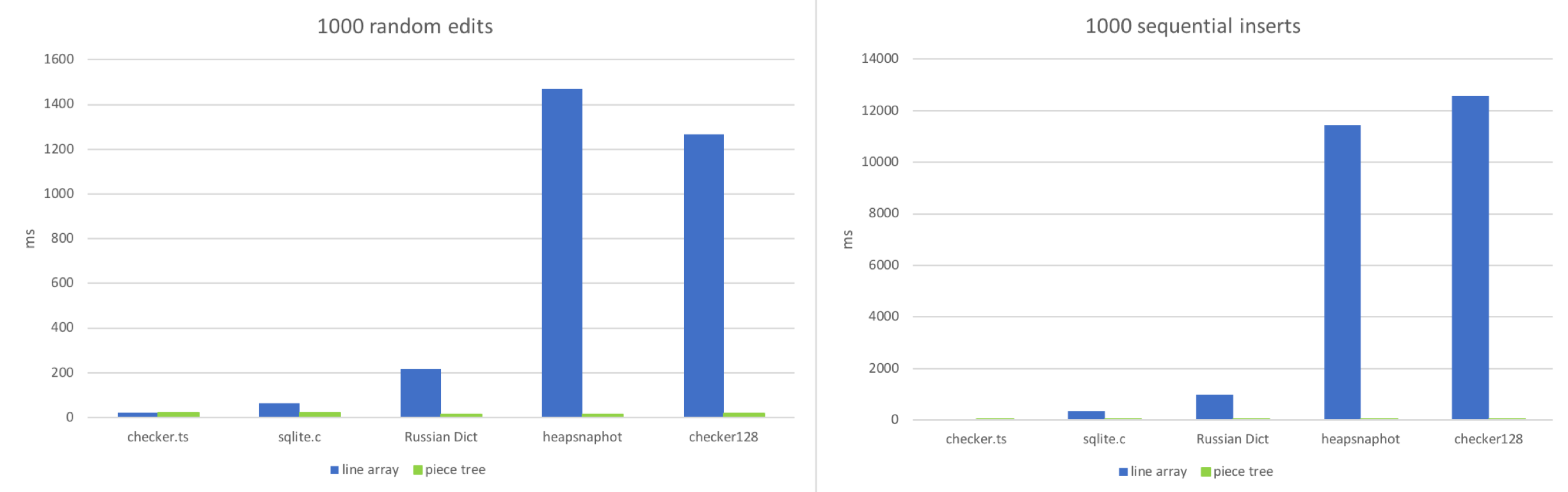
予想通り、ファイルが非常に小さい場合は行配列が勝ちます。小さな配列内のランダムな位置にアクセスし、100〜150文字程度の文字列を調整するのは非常に高速です。ファイルに行数が多くなると(100k行以上)、行配列は動作が重くなります。大きなファイルへの連続挿入は、JavaScriptエンジンが大きな配列のサイズ変更に多くの作業を行うため、この状況を悪化させます。ピースツリーは、各編集が単なる文字列追加といくつかの赤黒木操作であるため、安定した動作を示します。
4. 読み取り
私たちのテキストバッファで最も頻繁に呼び出されるメソッドは`getLineContent`です。これはビューコード、トークナイザー、リンク検出器、そしてドキュメントコンテンツに依存するほぼすべてのコンポーネントによって呼び出されます。リンク検出器のようにファイル全体を走査するコードもあれば、ビューコードのように連続する行のウィンドウのみを読み取るコードもあります。そこで、さまざまなシナリオでこのメソッドのベンチマークを設定しました。
- 1000回のランダム編集後、すべての行に対して`getLineContent`を呼び出す。
- 1000回の連続挿入後、すべての行に対して`getLineContent`を呼び出す。
- 1000回のランダム編集後、10個の異なる行ウィンドウを読み取る。
- 1000回の連続挿入後、10個の異なる行ウィンドウを読み取る。
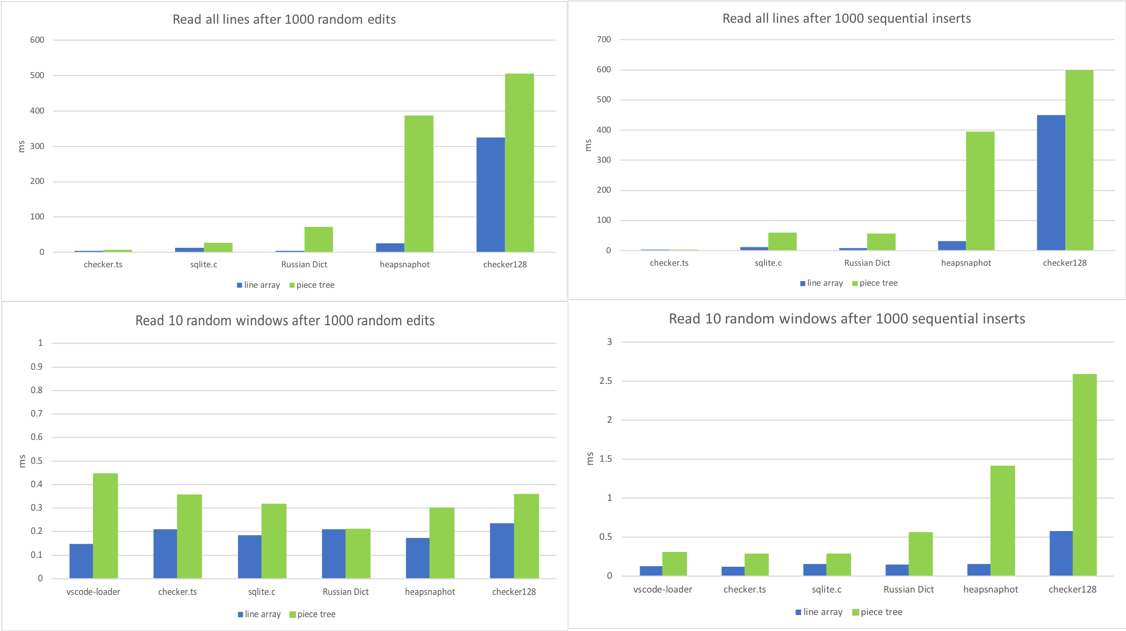
おお、ピースツリーのアキレス腱を発見しました。1000回もの編集が加えられた巨大なファイルは、数千から数万ものノードを生み出します。行の検索が `O(log N)` (Nはノード数) であっても、行配列が享受していた `O(1)` とは大きく異なります。
数千回の編集は比較的まれです。大きなファイルで頻繁に発生する文字のシーケンスを置換した後などに、そのような状況になる可能性があります。また、これは`getLineContent`呼び出しごとにマイクロ秒単位の話なので、現時点では懸念していません。`getLineContent`呼び出しのほとんどはビューのレンダリングとトークン化から来ており、行コンテンツの後処理の方がはるかに時間がかかります。DOMの構築とレンダリング、またはビューポートのトークン化は通常、数十ミリ秒かかりますが、`getLineContent`はその1%未満しか占めません。それでも、ノード数が多いなどの特定の条件が満たされた場合にバッファとノードを再作成する正規化ステップを、最終的には実装することを検討しています。
結論と注意点
ピースツリーはほとんどのシナリオでライン配列よりも優れていますが、予想通り、ラインベースの検索は例外でした。
学んだこと
- この再実装が私に教えてくれた最も重要な教訓は、**常に現実世界のプロファイリングを行うこと**です。どのメソッドがホットになるかという私の仮定が現実と一致しないことが毎回ありました。例えば、ピースツリーの実装を開始したとき、私は3つのアトミック操作、`insert`、`delete`、`search`のチューニングに集中しました。しかし、VS Codeに統合したとき、それらの最適化はどれも重要ではありませんでした。最もホットなメソッドは`getLineContent`でした。
- **CRLFまたは混在した改行シーケンスの処理は、プログラマの悪夢です**。すべての変更について、キャリッジリターン/ラインフィード(CRLF)シーケンスを分割するかどうか、または新しいCRLFシーケンスを作成するかどうかを確認する必要があります。ツリーのコンテキストで考えられるすべてのケースに対処するには、正しく高速な解決策が得られるまでに何度か試行錯誤が必要でした。
- **GCは簡単にCPU時間を食い尽くす可能性があります**。私たちのテキストモデルは、バッファが配列に格納されていると仮定しており、`getLineContent`が必要でない場合でも頻繁に使用していました。例えば、行の最初の文字の文字コードを知りたいだけであっても、最初に`getLineContent`を呼び出し、次に`charCodeAt`を行っていました。ピースツリーでは、`getLineContent`は部分文字列を作成し、文字コードを確認した後、その行の部分文字列はすぐに破棄されます。これは無駄であり、より適切なメソッドを採用するよう取り組んでいます。
なぜネイティブではないのか?
冒頭でこの質問に戻ると約束しました。
**要するに**:試しましたが、うまくいきませんでした。
C++でテキストバッファを実装し、ネイティブのNodeモジュールバインディングを使用してVS Codeに統合しました。テキストバッファはVS Codeで人気のコンポーネントであり、そのためテキストバッファへの多くの呼び出しが行われていました。呼び出し元と実装の両方がJavaScriptで書かれている場合、V8はこれらの呼び出しの多くをインライン化できました。ネイティブのテキストバッファの場合、**JavaScript <=> C++**の往復が発生し、その往復回数によりすべてが遅くなりました。
例えば、VS Codeの**行コメントの切り替え**コマンドは、選択されたすべての行をループし、1行ずつ解析することで実装されています。このロジックはJavaScriptで書かれており、各行に対して`TextBuffer.getLineContent`を呼び出します。各呼び出しで、C++/JavaScriptの境界を越えることになり、すべてのコードが構築されているAPIを尊重するために、JavaScriptの`string`を返す必要があります。
私たちの選択肢は単純です。C++では、`getLineContent`を呼び出すたびに新しいJavaScriptの`string`を割り当てるか(これは実際の文字列バイトのコピーを伴います)、V8の`SlicedString`または`ConstString`型を利用するかのどちらかです。しかし、V8の文字列型は、基になるストレージもV8の文字列を使用している場合にのみ使用できます。残念ながら、V8の文字列はマルチスレッドセーフではありません。
TextBuffer APIを変更したり、JavaScript/C++境界コストを回避するためにC++にどんどんコードを移行したりすることで、これを克服することもできたかもしれません。しかし、私たちは同時に2つのことを行っていることに気づきました。行配列とは異なるデータ構造を使用してテキストバッファを作成していることと、JavaScriptではなくC++で作成していることでした。そこで、成功するかどうかわからないことに半年も費やすよりも、テキストバッファのランタイムをJavaScriptに保ち、データ構造と関連するアルゴリズムのみを変更することにしました。私たちの意見では、これは正しい決定でした。
今後の課題
まだ最適化が必要なケースがいくつか残っています。例えば、「検索」コマンドは現在、行ごとに実行されていますが、そうあるべきではありません。また、行の部分文字列のみが必要な場合に、不必要な`getLineContent`呼び出しを避けることもできます。これらの最適化は段階的にリリースしていく予定です。これらのさらなる最適化がなくても、新しいテキストバッファ実装は以前のものよりも優れたユーザーエクスペリエンスを提供しており、現在は最新の安定版VS Codeのデフォルトとなっています。
ハッピーコーディング!
Peng Lyu, VS Codeチームメンバー @njukidreborn